

Today’s business forecast: sunny with a 100% chance of data driving our economy. It’s a fact that data leaders and organizations want to make data-driven decisions. In a recent report published by The Economist on the data-driven enterprise, in 2019, the U.S spent nearly $100B on big data and analytics tools. Let’s just say that we’re really invested in making BI tools work, particularly in our investment in the “single source of truth” technologies. However, we’re approaching diminishing returns in this investment as results aren’t yielding the promise we’ve all hoped to see.
As Data Mesh emerges as a paradigm-shifting methodology to access data across multiple technologies and platforms, it’s paramount to appraise it against data virtualization. For one thing, data virtualization has been a great tool to see a high-level overview of an organization’s overall data. Data virtualization is also more secure, cost effective, and sometimes more performant, than the traditional ETL – Extract, Transform, and Load. Overall, it complements Data Mesh concepts well and it’s worth taking a closer look.
Data Virtualization is a critical element to data management
First of all, data virtualization is a wonderful approach to data management, enabling organizations to construct, query, and weave together data – structured, semi-structured or unstructured – regardless of its distributed physical location and provide a single view of the combined data.
Just like the first principle of Data Mesh – domain-driven data ownership – was inspired by software development, data virtualization uses a DevOps-like approach to data management that enables fast provisioning and distribution of lightweight “virtualized” copies of entire databases for use as test data.
Data virtualization also supports the ability to access data while it’s migrating between systems such that operating system references to a file or object do not have to be modified as the file or object physically moves location.
How Data Virtualization Helps with Data Analytics
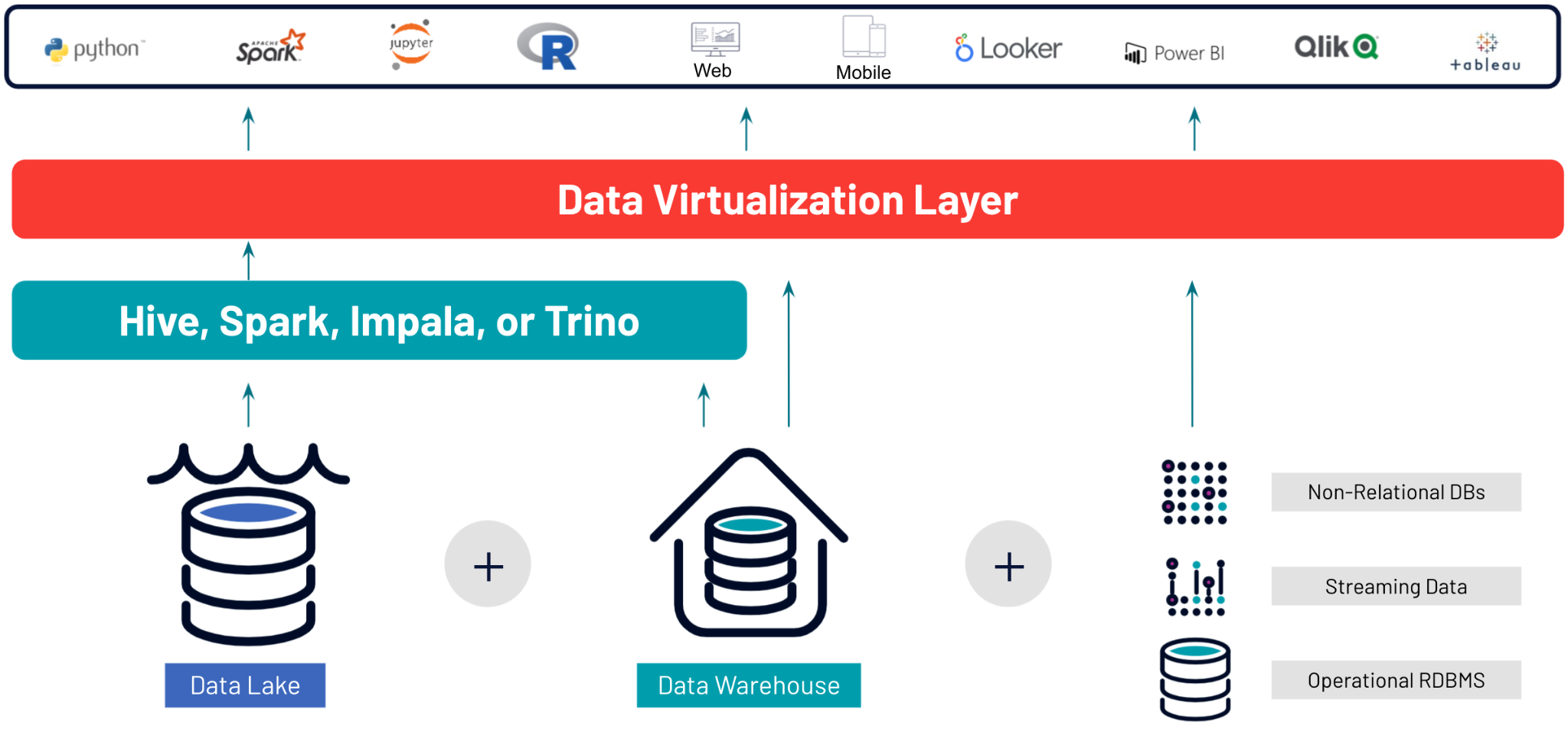
Data virtualization often has beautiful interfaces and creates an environment such that all relevant data sources, including databases, applications, websites, spreadsheets, content repositories and more, all appear and accessed as if they were in one place.
Essentially, data virtualization federates data – which pulls data together, from diverse, heterogeneous sources so that it can be virtualized, enabling capabilities and optionality such as pushdown optimization. Then, it presents the data in a consistent format – regardless of native structure and syntax – to the front-end application, like a business intelligence tool, either through SQL or by means of web services, or both.
Here’s an example using the single-source-of-truth approach: we’ll often see that data is in a data warehouse. If there’s new data from a business acquisition, the data might be in another data source. If we want to utilize it in our BI reports, with data virtualization, the user won’t have to write a bunch of ETL jobs. The big advantage is that you have broad access to various data sources. Instead of weeks or months, within days, you can have a new connection to that data source.
When Data Virtualization Doesn’t Scale in Performance
As we’ve seen, data virtualization is great and in fact, perfect for smaller scale needs. However, once a larger scope is needed, the requirements expand. To cope, data virtualization relies on the support of other technologies. For instance, it can build on their existing architecture with open source-based massively parallel processing (MPP) engines (i.e. Trino) and/or use an external query engine to query from object storage (data lake).
However, keep in mind, this band aid-approach creates a lot of unnecessary data duplication, overly complicated data architecture and increases time-to- insight. The existing workaround can certainly help larger organizations scale, albeit at the rate of diminishing returns. As we pointed out in the very beginning of this blog post, diminishing returns in our investments isn’t what data-driven and forward thinking organizations are seeking.
If a user has a data virtualization tool and runs a query – generally speaking and there are always exceptions – that query will run one CPU. That one query, will connect to one server and that one server will use one CPU. However, that one query can’t utilize all the resources of not just a server, but a large cluster. Essentially, that sole query is very constrained.
There is a more efficient way. With Starburst, for both on-premise and cloud servers, once a query comes in, that query can get split up (aka “splits”) to get more done with less. You can have a large table scan, where there are different splits, reading different sections of the table—in parallel (aka MPP)—where we can massively scale in performance.

How Data Mesh Scales Large Organizations
Scaling in performance is very much so in the spirit of Data Mesh principles. It enables frictionless access to data, across both cloud providers and on-premise data, ease of viewing data in different formats, eliminating copying data from one technology stack to another, and connecting to data, wherever it is.




