
Despite the investments and effort poured into next-generation data storage systems, data warehouses and data lakes have failed to provide data engineers, data analysts, and data leaders trustworthy and agile business insights to make intelligent business decisions. The answer is Data Mesh – a decentralized, distributed approach to enterprise data management.
Founder of the Data Mesh paradigm, Zhamak Dehghani defines it as “a sociotechnical approach to share, access and manage analytical data in complex and large-scale environments – within or across organizations.” She’s authoring an O’Reilly book, Data Mesh: Delivering Data-Driven Value at Scale and Starburst, the ‘Analytics Engine for Data Mesh,’ happens to be the sole sponsor. In addition to providing a complimentary copy of the book, we’re also sharing chapter summaries so we can read along and educate our readers about this (r)evolutionary approach. Enjoy Chapter One: The Inflection Point!
There are a few reasons why we’re at this juncture with data management. Currently, organizations still aren’t as agile as they would like to be. Remember how difficult it was to pivot with COVID-19? Meanwhile, the expectation to extract as much value from data has exponentially grown. However, let’s not forget that data emerges from multiple sources and data structures are so diverse that the technical complexities organizations face are no longer tenable.

Despite these conditions, transforming into a data-driven company continues to be a strategic imperative for many in the C-Suite. For instance, Intuit’s mission is to “power prosperity around the world as an AI-driven expert platform company, by addressing the most pressing financial challenges facing our consumer, small business, and self-employed customers.”
Here’s another revealing mission – AT&T’s guiding principle is to “incorporate human oversight into AI. With people at the core, AI can enhance the workforce, expand capability and benefit society as a whole.”
The bottomline is that companies want to leverage data-driven insights to enhance the business – whether it’s to provide the best customer experience, reduce operational costs and time, or to empower employees to make better decisions. To do this successfully, however, data-driven organizations must have data that’s voluminous, diverse, up-to-date and trustworthy so that it can quickly and accurately power analytic tools and machine learning models.
Previously, organizations looked at reports and dashboards and it felt sufficient and insightful. Today, organizations are expecting automated assistants, personalized healthcare, optimized real-time logistics, and accurate automated decision-making.
These ambitious expectations require a new approach to data management. Here are a few necessary technical parameters that would fundamentally change how organizations relate and interact with data:
- Frictionless access to data, across cloud providers and on-premise data
- Ease of viewing data in different formats, for reporting or to train a ML model
- Eliminate copying data from one technology stack to another
- Connecting to data, wherever it is
Data Silos: Operational Data vs. Analytical Data
The technical challenges that organizations bear today have roots in how we’ve organized data into:
- Operational data (transactional data that supports the business), and
- Analytical data (data that’s generated by way of running the business)
These two types of data mingle when companies collect operational data and transform it into analytical data. Then, “analytical data trains the machine learning models that then make their way into the operational systems as intelligent services.”
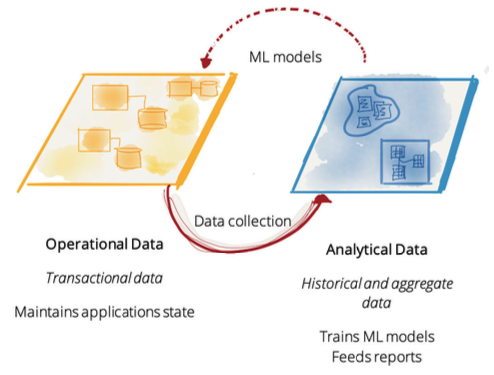
Operational and analytical data are essentially integrated, but remain separate and have led to a fractured data architecture between the two.
Zhamak writes, “The operational data plane feeds the analytical data plane through a set of scripts or automated processes often referred to as ETL jobs – Extract, Transform, and Load. Often operational databases have no explicitly defined contract with the ETL pipelines for sharing their data.”
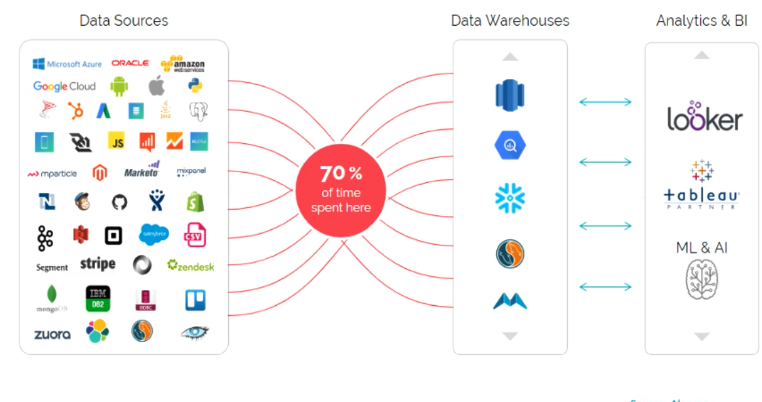
In practical terms, the enterprise data warehouse model is slower than it looks because data engineers spend 70% of their time transforming data between data sources and data warehouses. Hopefully, you’re beginning to see why we need a new approach to data management.
The Dismal ROI of Big Data and AI
In the latest 2021 New Vantage Partners report, The Journey to Becoming Data-Driven, a survey of senior executives on data and AI business adoption, what we learn is that despite all the investment and effort to build a data-driven company, the success rate is dismal.
In their report “only 26.8% of firms reported having forged a data culture. Only 37.8% of firms reported that they have become data-driven, and only 45.1% of the firms reported that they are competing using data and analytics.”
When 64.8% of companies surveyed invested more than $50MM in their big data and AI plans, we must have a better strategy.
Zhamak asserts, “The future approach to data management must look carefully at this phenomena, why the solutions of the past are not producing a comparable result to the human and financial investment we are putting in today.”
Looking Ahead: After The Inflection Point
Next time, we’ll examine what happens after we’ve realized that we cannot stay in this languishing state with data and how to chart a new path forward with how we aggregate, access and engage with data.
Read Along With Us!
Get your complimentary access to pre-release chapters from the O’Reilly book, Data Mesh: Delivering Data-Driven Value at Scale, authored by Zhamak Dehghani now.




