
Thirty years ago it was already commonplace for large businesses to have hundreds — even thousands of different database instances managing data from the variety of different applications running at that business. These database instances were rarely uniform in terms of software. Rather, they would typically include a mixture of different systems, such as Oracle, IBM DB2, Microsoft SQL Server, Teradata, Postgres, MySQL, etc. This sprawl of systems would lead to a feeling of data chaos within the organization. And worse: when the business would merge with another business, this chaos would double as a result of adding all of the new database instances from the business being merged, which often had overlapping functionality with existing data, further deepening the chaos.
This mess led to significant pain on behalf of the employees tasked with keeping track of all these database instances, and on behalf of those tasked with querying data across the database instances with overlapping functionality. Database federation and/or database virtualization was billed as the silver bullet that could alleviate much of the pain associated with this chaos. Imagine a single point of access through which all data across the enterprise could be queried and managed! How great life would be!
Unfortunately, none of the early data federation systems ever lived up to their promise. It turned out that building them was much harder than anybody expected. To understand why, let’s look at the theory and the practice of data federation systems in more detail via a simple example:
Why Data Federation is Hard
Imagine a grocery store that stores details about all transactions made in the store within an Oracle database. The store later opens a new online purchase business that is backed by a PostgreSQL database. An analyst wants to submit a query that returns the total number of cornflakes boxes sold in the past week across both parts of the business.
In theory, this should be a straightforward query to run. The query is submitted to the data federation layer, which forwards it to each system (shown in the blue arrows in the figure below), and then receives the results from the underlying systems, combines them, and returns them to the source of the query (shown in the green arrows).
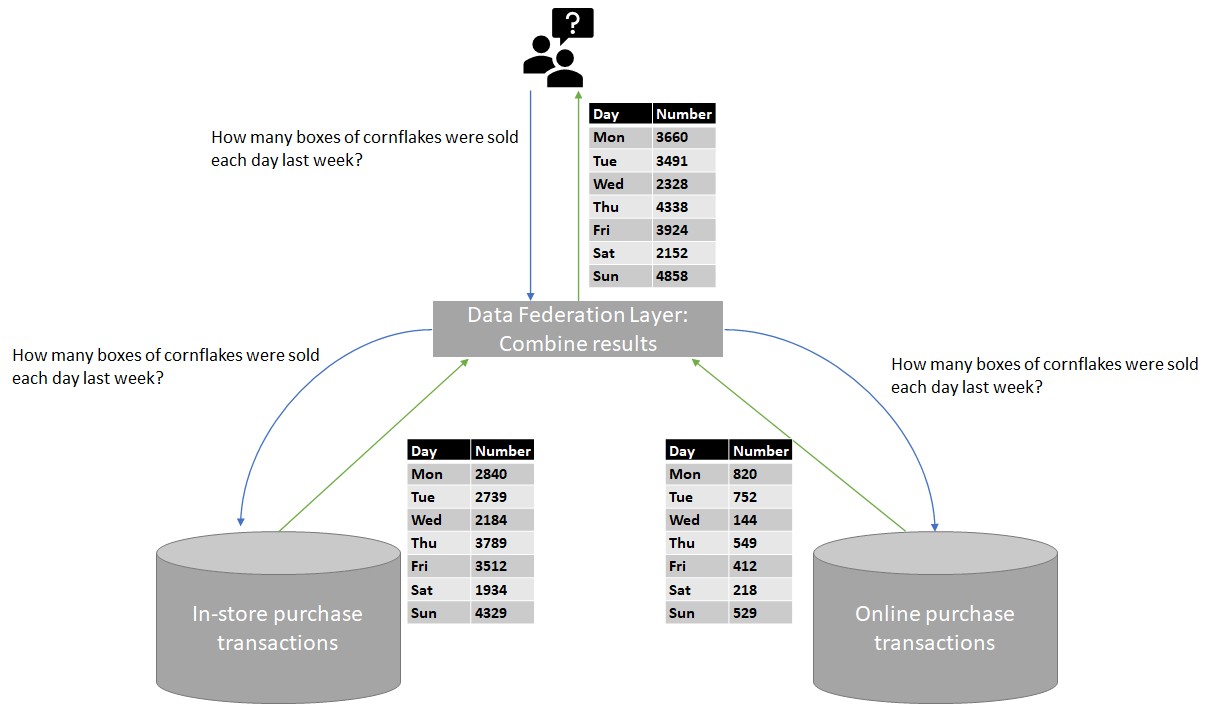
One problem that comes up, even for simple queries like these, is that each database system expects queries to be formulated in slightly different ways. Most database systems claim to implement one of the various versions of the SQL standard, and some actually do. But many systems are only inspired by SQL, and speak a slightly different dialect that differs from standard SQL along several nuances.
Even for those systems that fully implement the SQL standard, they invariably include their own extensions. In many cases, these extensions are extremely useful and are designed to suck the end user into a heavy reliance on these extensions, thereby making it more difficult to switch to a different database system at a later point.
Even basic features like extracting and interacting with the current date or time have notorious differences across systems. Therefore, our simple query we showed above, when translated to real SQL sent to Oracle and PostgreSQL would look something like the figure below:

Therefore, data federation systems were forced to become intimately familiar with all the SQL dialects used by the different systems supported by the data federation layer, in order to properly translate a user query into subqueries that could be sent to each underlying system.
To make matters worse, SQL is a declarative language. The client specifies what data should be returned, but makes no specifications about what algorithm should be used to find and combine data to be returned. Instead, every (legitimate) database system includes a query optimizer that parses the declarative SQL query, considers the many possible different options that exist for how the query could be processed, and chooses the lowest cost (i.e. fastest) option. This lowest cost option is then handed over to a query processor which executes the query according to this query plan.
Query optimizers are notoriously complicated and fragile/brittle and are usually the hardest part of a database system to implement well. For example, a query in which 16 tables are joined together must consider over 1020 different orders in which the tables could be joined — more than the number of grains of sand on all beaches and deserts on Earth — to find the best option. No system has the ability to check every option, so shortcuts and heuristics must be used, which often leads to optimizers choosing suboptimal plans.
In a data federation system, the federation layer needs to perform query optimization in order to determine how to take an input query and optimally create subqueries that can be sent to the underlying systems. Fundamental to the implementation of any query optimizer is its ability to correctly predict the cost (in terms of query performance) of each query plan option being considered. However, it is hard enough for a system to figure out the cost of its own execution plans. Having the query federation layer accurately predict the cost of query plans in the different underlying systems is nearly impossible. Therefore, what was already the most brittle part of a database system became orders of magnitude more brittle in data federation systems.
A third challenge in building the federation layer is the problem of joining tables that exist in different underlying systems. There are three basic approaches to performing such joins:
- Extract both tables being joined into the federation layer and perform the join there,
- Extract one of the tables being joined and send it to the other system, and perform the join there, or
- Extract just the join attributes and row identifiers of one of the tables being joined, and send to the other system. The join is performed there, and the row identifiers of the matching rows from the first table are returned. These row identifiers are then sent back to the first system to extract the remaining relevant attributes for these identified rows.
In the past, the network was always too much of a bottleneck to fathom option (1), since this option requires all the source data from both tables to be sent over the network to the data federation layer (we’ll come back to this point soon). Options (2) and (3) are far more network efficient and one of them was typically chosen. However, both of these options involve loading (or at least accessing) temporary data from an external source, which worked differently in every system, and which thus required more system-specific code.
A fourth challenge is that queries that spanned multiple systems often ran into difficulties when the semantics of the data managed by those systems varied subtly, which made unioning or joining data across systems dangerous because it could yield incorrect or inconsistent data.
The Tragic Obscurity of Data Federation
These challenges were ultimately too complex to overcome, and data federation has remained a niche option for decades. Instead, the centralized data warehouse emerged as the superior choice for the vast majority of use cases. Data would be extracted from the source systems and run through an ETL (extract, transform, and load) process during which data from different sources would have their semantics unified and be placed together in a single system, with a single SQL interface, a single query optimizer, and the ability to perform all joins locally.
It must be pointed out at this point that this outcome — where federated databases faded into obscurity and centralized data warehouses became the ultimate solution — is rather tragic. I have written in the past that centralized data warehouses are the primary bottleneck in scaling analytics within an organization. The human coordination required to get data into the warehouse and (to a lesser degree) to get data out of it, restricted the breadth of data available in the warehouse, and the agility to incorporate newly relevant data into an analysis task. Data warehouses have been stifling the ability of data analysts and data scientists to fully do their job for the entire history of data warehousing.
Today, as the data mesh approach to managing data within an organization continues to take off, where the emphasis has shifted towards allowing for more agility with respect to data management and eliminating centralized data management, data warehousing is going out of style, and data is becoming even more distributed across an organization. The need for federated data management is now present more than ever. But what about all of those failures from previous generations of data federation systems? Aren’t the challenges we described above still present? Are we doomed for failure?
The World Has Changed
The answer to these questions is that something very fundamental has changed, and the whole federated database management equation has shifted.
For decades, database research has shown when given a choice of sending data to a query or sending a query to the data it must process, the latter option is the correct choice. A query consists of code — a plan of action for how data must be accessed and processed. This code can be sent from the source of the query to the machines that store data in a network message consisting of only a few kilobytes (or less). Meanwhile, the data that is processed by a query may involve large tables consisting of terabytes of data. So the data is basically a billion times larger than the query which processes it. So what should be sent over the network? It’s a no-brainer! Of course the query should be sent to the data and not vice-versa!
This fundamental truth led to emergence of the “shared-nothing” architecture in which storage nodes were given sufficient memory and processing power in order to be able to process the queries that were sent to it. Turing award winner, Mike Stonebraker, used to go around and tell everyone that “shared-nothing systems will have no apparent disadvantages compared to the other alternatives”. To reiterate: of course the query should be sent to the data and not vice-versa!
And then the cloud happened, and a strange phenomenon emerged.
In the cloud, you pay for exactly the processing power (with its associated memory) that you use. The cost of letting machines stay idle become too apparent. Nobody wanted to pay for processing nodes (e.g., AWS EC2 instances) if they were not being used at capacity. So even when the processing nodes contained local ephemeral storage, nobody wanted to use that storage, since people wanted to spin up those processing nodes when they were needed, and shut them down when they were idle. Storing data in a place where it would disappear when its parent node would be shut down made little sense.
Instead, a new architecture emerged in which data was stored on cheap, long-term storage, that was designed for just that — storage. When a query came along that needed to process that data, processing nodes would be spun up that would suck the data out of storage (across the network) as it processed it.
And yes, it might be a billion times less efficient from a network communication standpoint to do this — to send the data across the network to processing nodes on demand, at query time. But network communication in the cloud is fast, cheap, and rarely a bottleneck. The economics of the cloud worked out such that this was more optimal than storing the data on nodes capable of fully processing queries. “Disaggregating storage and compute” became extremely popular.
It’s So Much Easier To Do Data Federation and Data Virtualization Now
The paradigm of disaggregating storage from compute is an enormous game changer for query federation and data virtualization. Almost all of the challenges we discussed above when implementing data federation systems are based on the assumption that a query needs to be pushed to the data. For example, why does the data federation layer need to learn the intimate details of all the different details of the SQL dialects? Because it has to send the subqueries to the different underlying systems. However, when data is pushed to the query, the data federation layer needs to know only how to extract data with high performance from the underlying system, a much smaller “ask”.
Similarly, when the query is pushed to the data, the data federation layer must reason about how exactly the different underlying system(s) will process a particular option for a subquery, which, as we discussed above, is an extraordinarily difficult task. But when data is pushed to the query, the data federation layer must simply extract the data and do the vast majority of query processing itself. Therefore, the query optimization task is essentially the same as query optimization in any database system (i.e. still complex and brittle, but no worse than what exists today).
The same point is made for the problem of join processing we discussed above. Option (1) is clearly the simplest option, but was rejected because it required pushing data to the query.
So the bottom line is that we live in a world where it is normal to send large amounts of data over the network during query processing — even in non-federated systems — in order to get data from storage nodes to processing nodes. The network bottleneck has almost completely disappeared. If so, data federation systems can do the same thing: extract data from the underlying systems over the network, and process everything itself. Of course, the extraction needs to be somewhat intelligent — some amounts of simple data filtering should be done by the underlying system. But still, this makes data federation systems orders of magnitude simpler to build.
Conclusion
Not all of the challenges of implementing data federation systems have gone away. Dealing with different data semantics of the underlying systems is still dangerous. And the network is only not a problem within a region. Cross-region and cross-cloud communication is still expensive, and data federation/virtualization systems must be cognizant of that when implementing query processing engines. Nonetheless, it is a whole lot easier to implement data federation and data virtualization today than ever before. A technology that has been relegated to a niche market for so long is now finally taking off.
Ideas expressed in this post are based on research supported by the National Science Foundation under Grant No. IIS-1910613. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author and do not necessarily reflect the views of the National Science Foundation.




