
Note: I start this piece with some technical background that has nothing to do with the data mesh, and is only relevant to data warehousing insofar as it explains how the parallel database systems that often underlie data warehousing solutions usually work. The main thesis of this article does not begin until the fourth paragraph. But the first three paragraphs serve as important background behind this thesis.
There is one rule, pretty much the only rule, that determines success in scaling data systems: avoid coordination whenever possible. This one rule neatly summarizes my entire career until this point — the quarter century I’ve spent teaching, innovating, and building scalable data systems. At the end of the day it all comes down to one thing — avoiding coordination.
From a technical perspective, it is obvious why avoiding coordination is so important. No CPU processor can single-handedly handle the resource-intensive workloads that are required in modern data systems. So a scalable system necessarily requires multiple processors, often on the order of thousands or more, typically distributed across multiple independent servers with their own memory and often their own stable storage. When each processor can run completely independently of the other processors, you automatically get linear scalability. If you double the processors, you double the workload the system is able to handle.
The only thing that gets in the way of linear scalability is coordination. If one processor needs anything from another processor, whether it be data, metadata, lock permission, scheduling permission, or anything at all such that it cannot proceed until it receives what it needs from the other processor, that processor is prevented from being able to continuously make progress, and this introduces scalability bottlenecks. Every system that I’ve been involved in building or designing — from scalable transaction systems such as Calvin/Fauna, H-Store/VoltDB, Bohm, Orthrus, and SLOG to scalable data analytics systems such as C-Store/Vertica, HadoopDB/Hadapt, and Borealis, the primary innovations behind these systems involved making each processor as independent as possible.
All of this is why the concept of a “data warehouse” is one of the most hypocritical ideas on the face of the planet. Modern data warehouses are typically built using cutting edge scalable software using the architectural principles that have emerged from my lab along with the many other research labs world-wide that are innovating in the area of scalable systems. Tremendous care is taken to achieve near linear scalability of the software, allowing potentially thousands of machines to operate in parallel with minimal communication and coordination. The improvement in the scalability of these systems and the overall progress that has been made in the past few decades has been stunning, dizzying, and inspiring.
And yet we go and tell businesses to deploy these super scalable systems inside an organizational structure that is the very antithesis of scalability: the data warehouse. Anybody who has been involved in the deployment of a non-trivial enterprise-wide data warehouse knows that the endeavour is filled with coordination. Organizationally, it is a centralized behemoth, a single source of truth. Centralization and parallelization are antonyms. Scalability requires independent units working in parallel, while centralization introduces coordination, resistance, and inertia.
Getting data into a data warehouse typically requires a great deal of coordination between those in charge of the source system data, those in charge of data governance, data quality, master data management, data integration, those in charge of the data platform, devops, and the data engineers or data scientists that are driving the incorporation of this new data. It is routine to experience delays of multiple-months or longer to get data included in the data warehouse. Making changes to the layout or schema of the data once it is there is a similarly time consuming and coordination-heavy process. Extracting data from the data warehouse — especially when it involves connecting tools to the data warehouse — similarly requires significant amounts of coordination. Running queries over data in the data warehouse are blazing fast and scalable. Everything else organizationally about the data warehouse is slow and unscalable. Is there any wonder why so many data warehouse projects have oversold and under-delivered? How can it be that the world’s experts in scalability can continue to tell customers to deploy their software in such unscalable environments?
The data mesh
In truth, organizational data management processes have been much slower to modernize than technical capabilities. But Zhamak Dehghani has introduced an idea — the data mesh — that in retrospect, seems so obviously the right thing to do, it’s hard to believe that the data warehouse has managed to dominate for so long until now.
Dehghani explains the idea in her own words in an extended 6500 word treatise. Below I will summarize the idea, through my own scalability lens.
Deploying a new data set into a data warehouse involves three primary functional capabilities:
(1) ingesting the raw data from one or more data sources,
(2) transforming and cleaning the data to meet organizational data quality requirements, and
(3) applying a data model over the data through which it can be accessed and served to client processes.
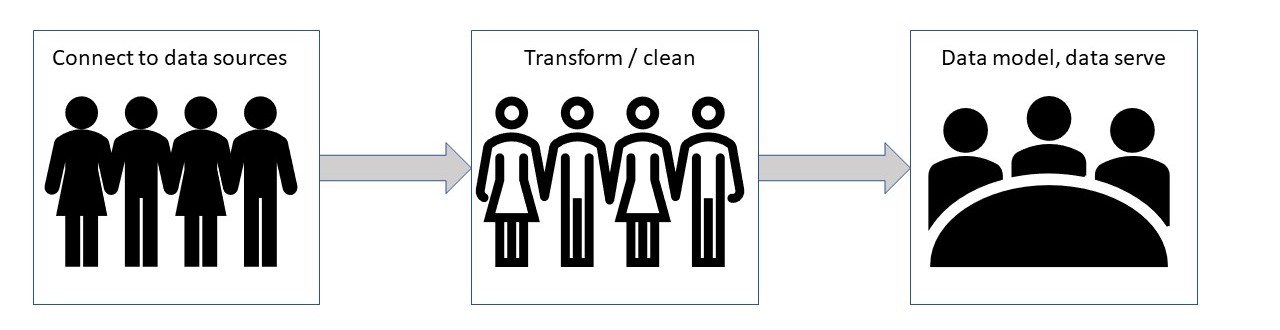
When this pipeline of functionalities becomes an organizational bottleneck, an attempt is usually made to parallelize these different functional capabilities — i.e. deploy a team of human resources focused on task (1), and separate teams for tasks (2) and (3) respectively, as shown in the diagram above. Each team operates fairly independently and in parallel, focusing on a specific functional capability. However, each team requires the output from the previous stage of the pipeline before they can begin to process a particular data set.
The data mesh does for human teams what the parallel database systems do for “teams” of computers/servers.
In order to explain the significance of the paradigm shift that is brought by the data mesh, I will use an analogy. This analogy may only resonate with those people who have experience with, or have taken a class on parallel data processing. Nonetheless, the basic idea is simple, and I encourage all readers — even those without experience in parallel database systems — to make an attempt to understand the analogy.
I said above that modern data warehouses are built on top of extremely scalable parallel database systems. It is only the organizational infrastructure around the technology that doesn’t scale. So let’s take a closer look at how parallel database systems scale so well.
Let’s say that a simple query is submitted to a parallel database system that calculates the total of the game points of all users under the age of 20 in a game application. This query performs three operations on a dataset:
(1) extract relevant attributes from a set of records
(2) filter this set of records so that only those that satisfy a particular condition (age < 20) are returned
(3) perform an aggregation (sum) on this data.
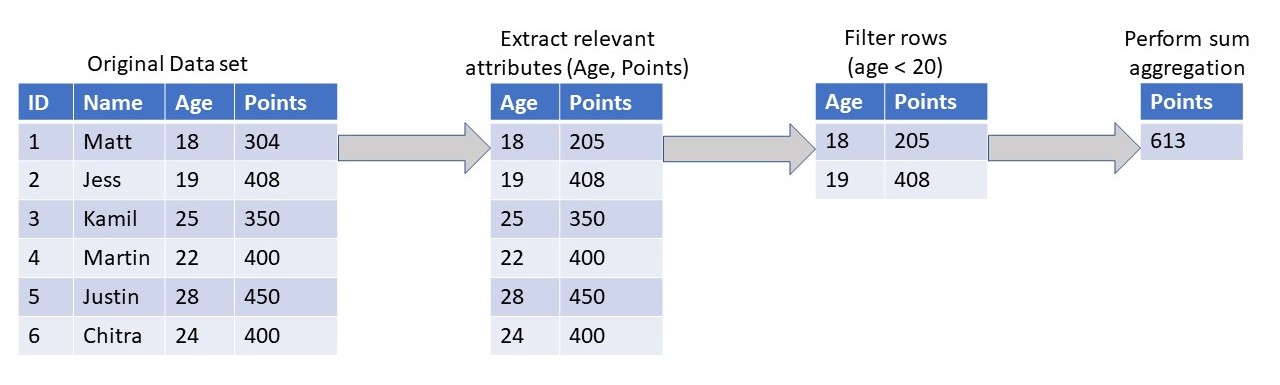
If we were to parallelize the processing of this query the same way we parallelize the organizational functionality of a data warehouse, we would divide the functional work across different processors. Task (1) gets assigned to processor (1), task (2) to processor (2) and so forth. Each processor performs the task assigned to it, passing its results to the next processor in the pipeline before working on the next batch of data.

This method of parallelizing work is natural, straightforward to understand, and decades ago, some systems actually performed parallel processing in this way. But of course, any student who has taken a half-decent class on scalable database systems, knows that this is absolutely the wrong way to scale a system. First of all, this method of parallelization creates a maximum amount of parallelism possible: the number of operators. In our example, we can keep 3 processors busy — doing each of the 3 tasks. The remaining 997 processors in a 1000 processor system would be sitting idle. Furthermore, after performing task (1) for a record, that data is currently in cache (or even on the CPU register) and ready to be processed. Why would we not want to perform the remaining operators on this record while the context is fresh, instead of sending the intermediate data to another processor which has to spend time bringing the record into cache before it can continue processing it?
In practice, the right way to scale is to partition data and allow each processor to work on a separate partition. Each processor performs all piplineable tasks on the same data — in our example, it would do the extracting, filtering, and initial aggregation immediately one after the other as each record flows to the CPU from cache. All the processors are working completely independently, in parallel, with no coordination except a small amount at the very end of query processing when the partial aggregates need to be combined.

The data mesh notes that human processors involved in data warehousing tasks are no different than silicon processors. Why would we want to limit parallelism and have only three teams working on the three functional tasks listed above (ingesting, transforming, serving)? Why would we want to have a separate team do the transforming, when that team would lack the appropriate context and expertise on the data that the sourcing team generated? Similarly, the data serving team lacks the context that the data transformation team owns. Parallelizing data warehouse tasks in this way introduces coordination bottlenecks as each team attempts to gain the appropriate context that the team that worked on the previous step in the pipeline already developed.
The right way to scale silicon data processing is to partition the data. And the right way to scale the human effort in maintaining data sets is to partition the data.
The data mesh takes the page directly out of the parallel DBMS playbook, and applies it at the business organization level. Allow teams to develop expertise in particular datasets, and empower them to take full and complete ownership of that data. They bring together datasets that are relevant for their core competency, perform the extractions, transformations, and make the data accessible not only for their own needs, but delivered as a finished product that can be accessed by other teams within the organization as well.
One team sources and combines data from business events generated from a brick-and-mortar component of the business. Another team focuses on the online business events. A third team uses both these two datasets along with other data sources to determine a mapping between brick-and-mortar customers and online customers. A fourth team focuses on social media data. A fifth team on identifying key influencers. And so on and so forth. Many teams, working independently, but potentially accessing the finished data products generated by other teams. Data governance and data integration become distributed endeavors, relying on organization-wide best practices and shared identifiers.
But there’s a catch
One key difference between humans and machines is that humans tend to be much more heterogeneous. Each team may have substantially different levels of technical expertise and preferred data management tools. Some teams prefer working with data processing tools such as Spark or Hadoop, other teams with database systems such as MySQL or Oracle, other teams with raw data sitting on a file system. Forcing particular technologies on data mesh teams is a form of coordination that limits their ability to work independently and focus on their core competency.
The natural outcome of the data mesh is therefore a potpourri of data sets, organized in different formats, stored in different types of systems, located in various public clouds, on premise, or within SaaS systems. Without the right data infrastructure technology, the data mesh will lead to an overwhelming number of data silos, that makes accessing the data products from other teams inconvenient, intractable, or infeasible. All the good of the rapid progress made possible by giving teams independence and self-service will get repaid with hard walls between data products that are difficult to surmount. This danger of the data mesh is perhaps the biggest reason why the data warehouse has managed to survive for so long, despite the hypocrisy.
Fortunately, the technology behind data management systems has made significant progress towards becoming agnostic to how the data is stored. In the previous generation, these systems needed to control everything — they needed to ingest the data and manage it locally in order to serve queries with high performance over this data. The query processing engine has typically been tightly coupled with the storage layer using a monolithic architecture. Accessing data stored outside the system has typically been possible only through slow and cumbersome system extensions such as “external table” mechanisms.
Increasingly, the parallel query processing engine is becoming independent of data storage. In some systems, such as Presto, Trino, and Starburst, the query processing engine has become so completely independent that they don’t even come with any data storage whatsoever. The data consumer simply points these systems to data sources — whether they be sitting as Parquet files in S3 object storage, database tables in a RDBMS, or an API to a SaaS system — and these systems are able to extract and scalably process data using state-of-the-art parallel processing techniques.
Such systems are integral to the long term success of the data mesh. While the data mesh encourages the generation of a potpourri of data sets, data management systems that can query this potpourri, regardless of the data format, regardless of the underlying system in which the data is stored, and regardless of the physical location of the data are critical. Indeed it is perhaps the most important tool necessary to avoid the silos and chaos that would otherwise arise.
Given that the technology that enables the data mesh to be implemented without “the silo catch” now exists, the remaining justifications for the continued existence of the centralized data warehouse are starting to disappear. It is time for the data mesh to live long and prosper.
Ideas expressed in this post are based on research supported by the National Science Foundation under Grant No. IIS-1910613. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author and do not necessarily reflect the views of the National Science Foundation.




