
Microsoft has migrated thousands of customers to its Azure cloud platform and has quickly become the second most popular cloud provider. Companies have easily transitioned their Windows and non-windows infrastructure including their analytics and operational platforms.
There are different services within the Azure cloud that can provide analytical services such as Azure Data Lake Storage (ADLS), Azure Synapse and Microsoft SQL Server. Ideally, most of a company’s analytical data would be stored in ADLS due to its low cost and high performance and stored in an open columnar format such as Apache ORC or Apache Parquet. This allows true separation of compute and storage without “data lock-in” as we like to call it.
Moving from on-premise data lake to Azure’s ADLS Gen 2 storage
Starburst has helped many customers transition from their on-premises data lake to Azure’s ADLS Gen 2 storage. Adding a high performant, high concurrent query engine on top of this storage allows a company to provide an easy-to-use SQL-based tool to query data in a variety of locations.
In the diagram below, we illustrate a query consumption layer on top of a data mesh in which different organizational domains store their data in different data storage locations such as ADLS, Synapse, SQL databases such as SQL Server, and even NoSQL and queuing systems such as Kafka.
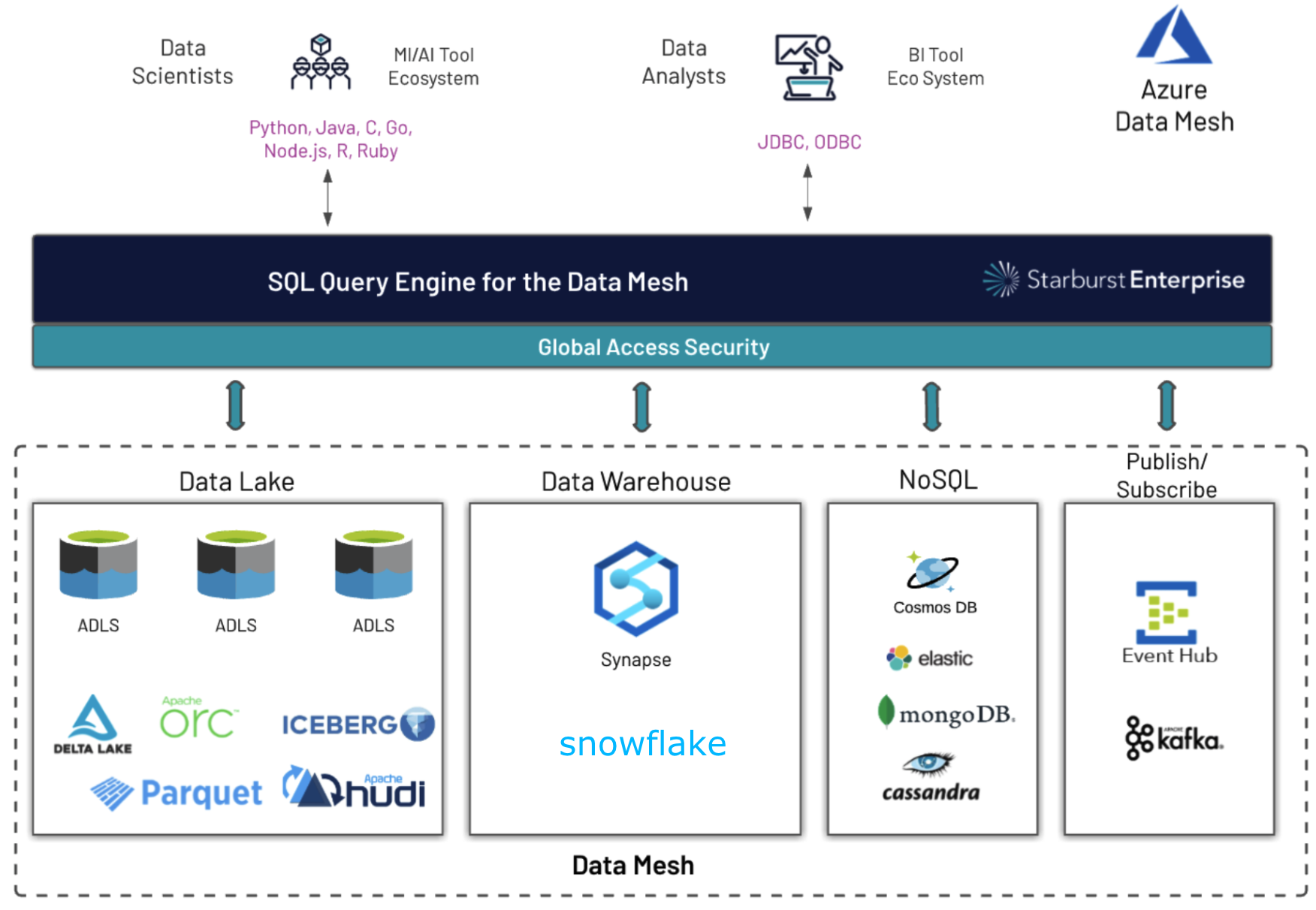
Instead of moving data from one source to another just to query it, Starburst allows you to query the data where it lives with simple sql such as:
select region,sum(tot_sales) from adls.sales, sqlserver.regions;
Choosing the storage location for your data is mostly dependent on the expectations from the consumers of the data which include uptime, performance and quality/volume of data. Whether your data is in ADLS, Synapse, Cosmos DB or even Event Hubs, Starburst can join this data together using standard SQL queries leaving the headaches of ETL/data migration in the past. See all of our connectors here.
Aggregations/Rollups and Sandboxes
Additionally, Starburst’s ANSI SQL language support makes it an excellent choice for creating and managing tables in your data lake as well as many of the 40+ connectors to other data sources. The types of tables can be integration, rollup, aggregation and even sandbox tables for users to experiment and create sample data sets with. Combining and persisting data from multiple sources is table stakes for any modern analytics architecture and Starburst makes it super easy using industry standard sql.
Starburst Cached Views
Cached views allow tables from many different data sources to be cached in other connectors such as ADLS Gen 2. This allows for much higher performance using parallel reads from the Starburst cluster workers. This can also help burden the impact on the source system from many users querying it at the same time.

In the diagram above, the customer table is replicated to ADLS every hour and queries to the SQL Server table “customer” are automatically redirected to ADLS greatly improving the performance and reducing the impact on the database. The source database can be located anywhere including an on-premises data center.
Starburst Delta Lake Connector
Modifying data in a data lake has always been a challenge. Delta Lake provides a transactional layer on top of ADLS which includes many benefits such as ACID transactions (update, delete,etc..), and large performance improvements. With our latest Starburst Enterprise release, we have introduced update, insert and delete of Delta Lake data in ADLS. This is tremendously important for not only updating existing data in your data lake but for compliance such as GDPR.
Starburst Stargate
Large enterprise companies often have data spread across different locations such as on-premises, cloud, and even multi-cloud. Starburst’s Stargate allows clusters in different locations to work together to process queries locally and reducing egress costs and greatly improving performance by processing the data locally.
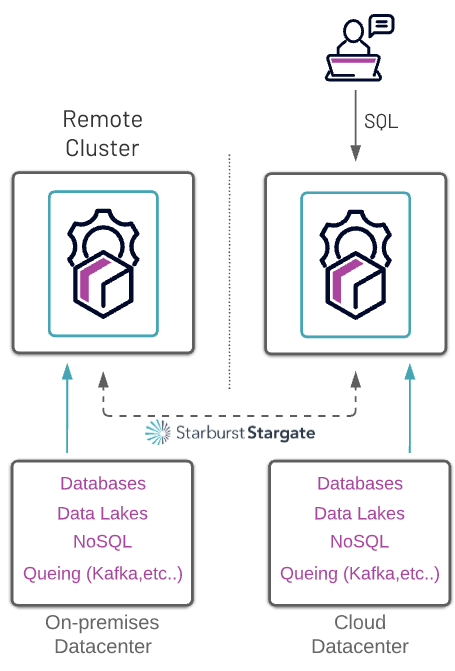
The best part of Starburst Stargate is users don’t have to worry about where the data lives, they just write normal sql queries to get the answers they are looking for.
Conclusion
As Microsoft’s Azure platform continues to grow and enterprise companies create and migrate data, Starburst provides an easy way to query that data wherever it lives. This provides a one-stop-shopping solution to query data in a variety of sources and locations. With the additions of Stargate and Views, we help you manage the complexity of providing relevant and timely data to all of your users using industry-standard SQL.
How to create a cost-effective Azure lakehouse data strategy
Azure Data Lake Storage (ADLS) is a great technology that provides low-cost, redundant storage.




