
Recently I presented with my colleagues, Justin Borgman, CEO of Starburst, and Daniel Abadi, Chief Scientist, at The Data and AI Summit by Databricks and discussed the need for the data lakehouse architecture. The data lakehouse option is a very promising paradigm for data management because it combines the benefits of a data warehouse with the benefits of data lake. With Starburst on top, organizations are better able to analyze their data stored in data lakehouses.
The Need for a Better Approach to Data Management
The data management approach of the past, the data warehouse, requires too much copying and moving of data. With the data warehouse model, there is a lot of preparation and ETL (Extract, Transfer, and Load) necessary for data analysis and; therefore, the time-to-insight is often very slow. So, when businesses turn to their data analysts with a question, they aren’t able to get the answer as quickly and efficiently as they would like.
Traditionally data warehouses have been used to consolidate data; however, moving all this data into one central EDW (Enterprise Data Warehouse) is in many cases not practical: the time required is too long, it is a closed system which causes vendor lock-in, and it is typically very costly. In addition, data in these warehouses is harder to share within an organization.
Benefits of a Data Lakehouse
Data lakehouses have become a solution for some of the problems that a traditional data warehouse has. With a data lakehouse, business intelligence, reporting, data science, and machine learning experts are all able to work together on the same data, in all its different forms, within the data lakehouse. Furthermore, one of the main benefits of a data lakehouse is optionality: Justin highlighted this important change in data architecture which, “[allows] you as the customer, to ultimately have control and ownership over your data.” This optionality is three fold. Firstly, the lakehouse extends a data lake strategy. Customers can leave data in the lowest cost storage, no data movement is required, and bring data governance to the data lake. Secondly, you can use open data formats whenever possible. By using open file formats, you can work with multiple tools to access the same data and avoid vendor lock in. Lastly, a lakehouse enables a data consumption layer. This is where Starburst comes into play by being able to access data where it lives and still be able to query all your data together.
Data Sharing: A Critical Progression
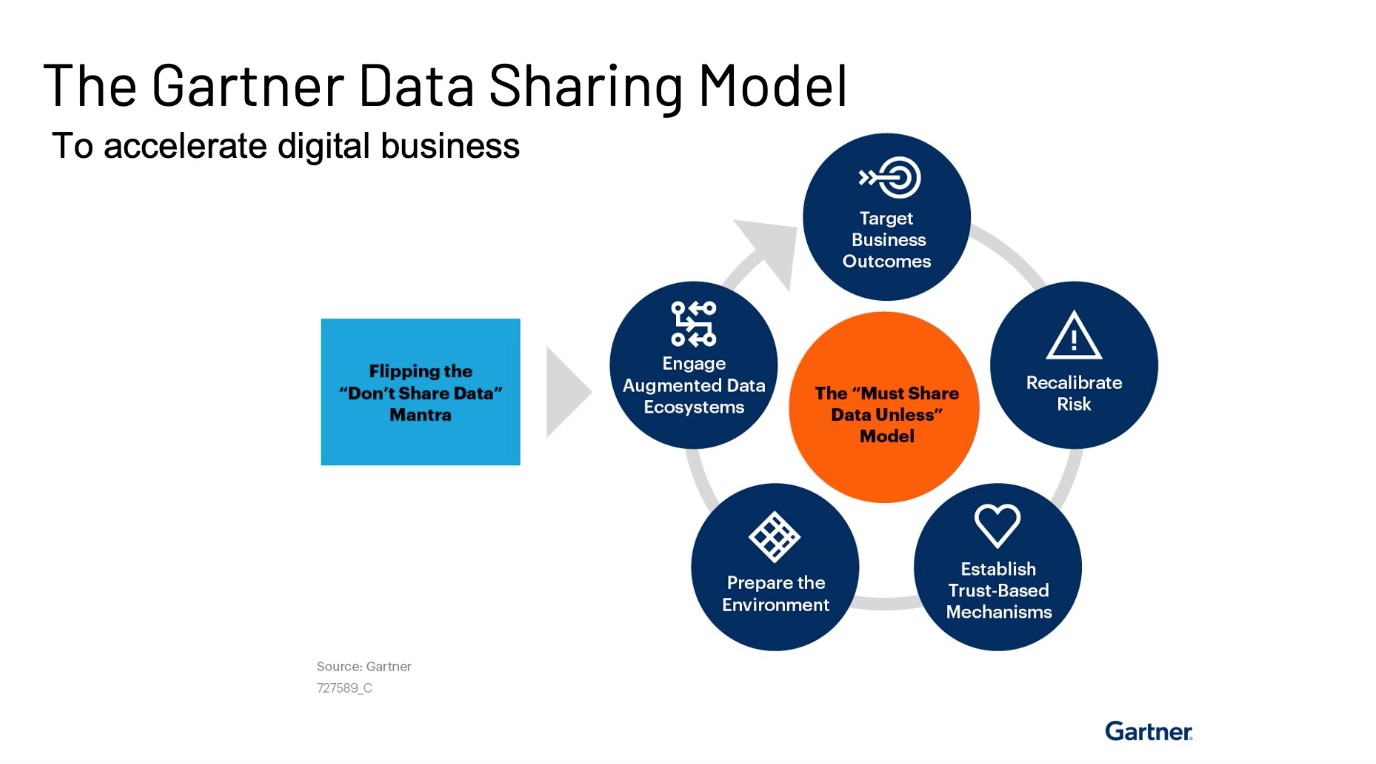
Another important aspect of the data lakehouse is the ability to easily share data. Right now, data sharing is a critical process. There has been a flip in the ”Don’t Share Data” mantra. Daniel described this mindset change as, “[Earlier] companies would worry about the risks of sharing data both within an organization and across organizations. Now it’s the opposite, now companies have to worry about the risk of not sharing data.”
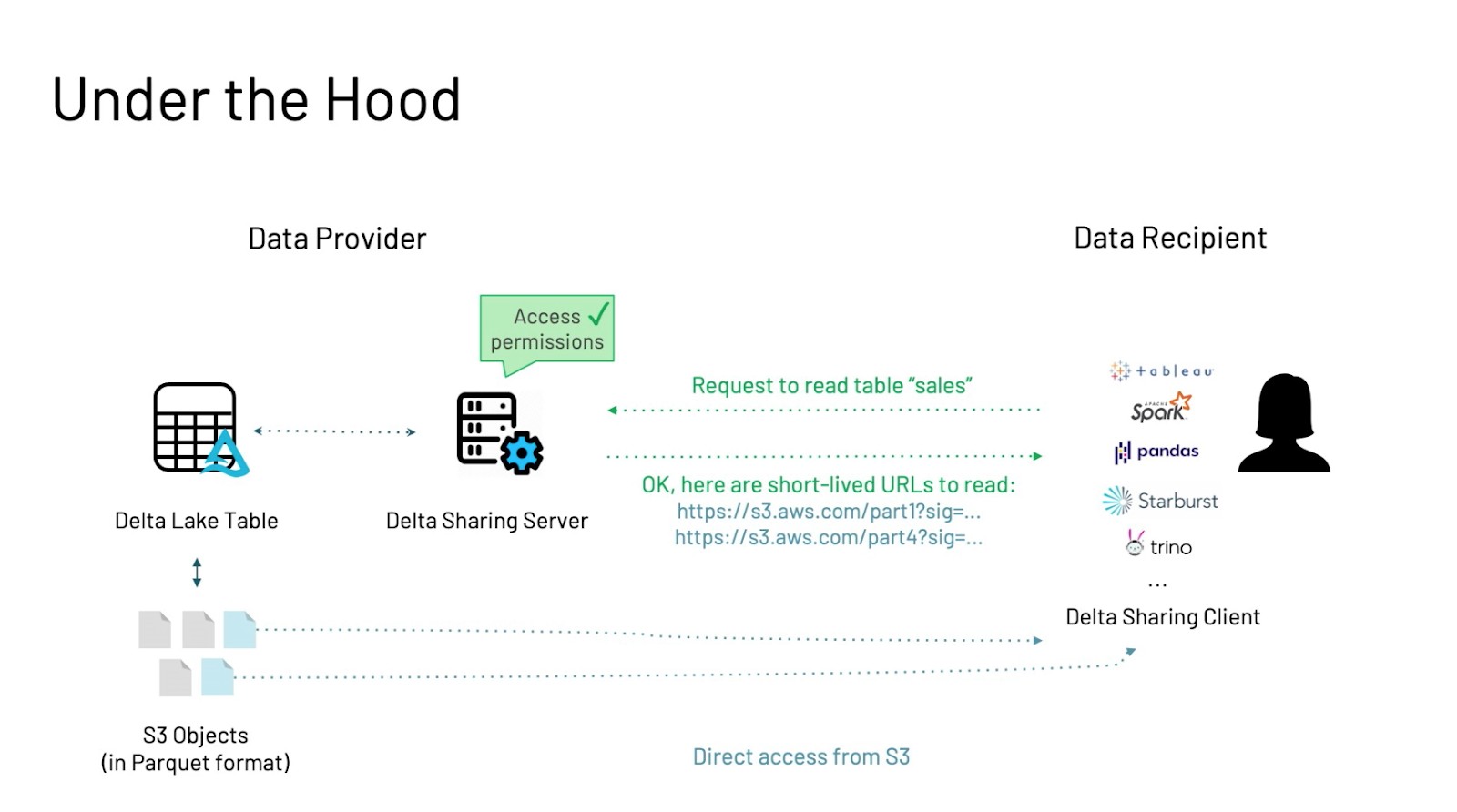
This is where Delta Sharing comes into the picture. Customers have the ability to share live data without having to copy it out. It also supports a wide range of clients using existing data formats, and it is secure and scalable. Delta Sharing works by communicating via a Delta server in order to access different data sets. The customer makes a request to the server for a data set. The server then responds with short-lived URLs that can be accessed directly from the data consumer. This allows for external data to be incorporated into data analysis.
Why Delta Lake?
Delta Lake helps to address many gaps in the data warehouse. It is an open source table format which means that there is no vendor lock-in. It is also stored as Parquet file format which has many the benefits of warehouse technologies, and you can deploy it from anywhere you want. In addition, it has time travel features, exposes metadata and statistics, and allows for data skipping and z-ordering to improve query performance
Why Data Lakehouse?
The data lakehouse combines the best of the data lake and data warehouse. It is, again, open source, but is also high performance, reduces data movement and overall costs, and better supports AI and ML workloads.

Trino and Starburst’s Native Delta Lake Reader
Trino is a an open source high performance MPP SQL engine that has proven to be scalable and has high concurrency. It also allows for a separation of compute and storage, allows for greater optionality, and the ability to deploy it anywhere.
Starburst’s native Delta lake reader supports Delta transaction logs, data skipping and dynamic filtering, and it optimizes queries using file level statistics. The performance is much faster than the speed achievable with just Parquet file format. In a typical flow, data is ingested as it arrives into the system, it is then refined and aggregated, which leads to more efficient data analysis and machine learning later on. You have the ability to connect to a variety of BI and SQL tools and can run all operations from Starburst and Trino directly.

Data Lakehouse in Practice
During the pandemic, the health care community was hit hard with the need to turn digital and absorb an abundance of data in an efficient and comprehensible way. EMIS Health needed to understand the spread of COVID, while also monitoring other diseases. In addition, once vaccines were made available, there was another need to track the vaccine rollout. This meant that a lot of data from a variety of sources needed to be queried quickly. The query needed to be flexible, secure, and scalable. It was also needed in real time, something always ready for analysis. They found that the data lakehouse combined with Starburst provided a solution to all of their data needs, and is the future of their data analytics.




