
The Starburst Enterprise 2021 Q3 release (360-e LTS), provides Starburst customers with new capabilities alongside more advanced connectivity, improved performance, and enhanced security.
As always, this major release combines features that have been contributed back to the open source Trino project, as well as being curated for Starburst Enterprise customers. To experience this latest release first hand, please visit our download site.
Some notable features for this release include:
Starburst Cached Views
Starburst Cached Views are a collection of performance features for more efficiency, and less work. These features add caching capabilities across different data sources that are transparent to the end user. For example, data from a relational database can be cached on Amazon Simple Storage Service (S3). The end user still issues the same query to the relational source and Starburst redirects the read operation from the relational table to the cache in S3. Starburst Cached Views allows customers to incrementally update new rows of data, without needing to execute a full refresh. Starburst Cached Views can now improve read performance up to 20x and update 100’s of times faster.
Starburst Cached Views is a feature suite that includes:
- Table scan redirection allows read operations in a source catalog to be transparently replaced by reading the data from another catalog, the target catalog.
- The cache service manages the configuration and synchronization of the source and target catalogs along with the cache service CLI, which provides an easy management interface for the cache service as a command line tool.
- Materialized views store the results of a query locally within your cluster, improving query speed. The cache service can manage automatic refreshes based on your desired schedule.
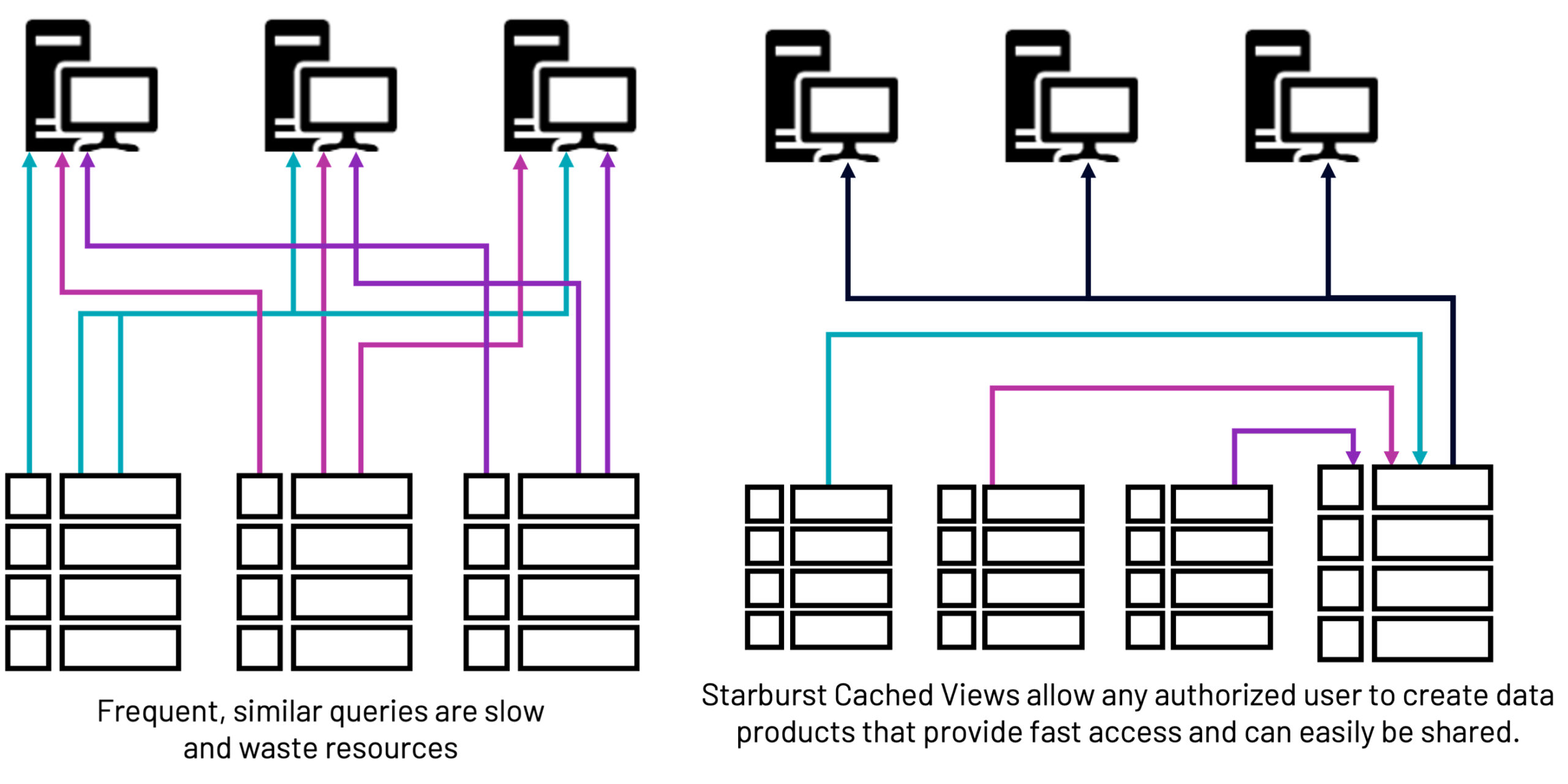
This release adds materialized views into our existing Cached Views feature, and can improve time to insight by 100x. They can be used in situations where direct access to source data is slow or inconsistent and can also reduce the impact on the data source. It is being offered via standard SQL, which makes self-service caching accessible to a wider set of users within our customers’ organizations.
Now, using Cached Views, analysts won’t wait for BI to rerun complicated queries over and over again. They simply access the saved materialized view directly and the analysts experience significantly faster time to insight. Even more impressive, table scan redirections are not simply copies of data in just one snapshot in time – they will still work when a use case requires real-time data access.
Starburst Cached Views also benefit customers adopting a data mesh strategy and require the ability for domain experts to access data sitting in other domains or data sources. Now, domain experts can create a cached view simply using SQL and present their data to other teams in minutes.
Faster Parquet reader
As organizations create, manage and consume more and more data, lakehouses allow organizations to cheaply store large amounts of data while giving users the fine-grained control they need to keep their data up-to-date, and compliant with data regulations. In this release, Starburst is excited to announce an improved Parquet reader to support lakehouse architectures.

Parquet is a columnar file format designed to support fast data processing for complex data that has become the most dominant format. Now, our read performance has improved an average of 20%, and for some queries by as much as 30%. With our improved Parquet reader, Starburst has reinforced its position as the leader in analytics and performance on data lakes.
Delta Lake performance optimization
Data warehouses are organized, structured and capable of running fast analytics, but are very expensive and cumbersome. Data lakes on the other hand are flexible, large and cheap, but hard to manage and update and can often become a swamp. The lakehouse is intended to combine the advantages of data warehouses and data lakes (speed and flexibility) without the aforementioned challenges (price and ease of management).
Delta Lake allows organizations to cheaply store large amounts of data while giving users the fine-grained control they need to keep their data up to date and compliant with data regulations. Starburst has continued to invest in the Delta Lake connector to help customers close the efficiency and speed gap between data warehouses and data lakes. We make it more efficient to join data within the lake, and provide the optimal path for queries to be run.
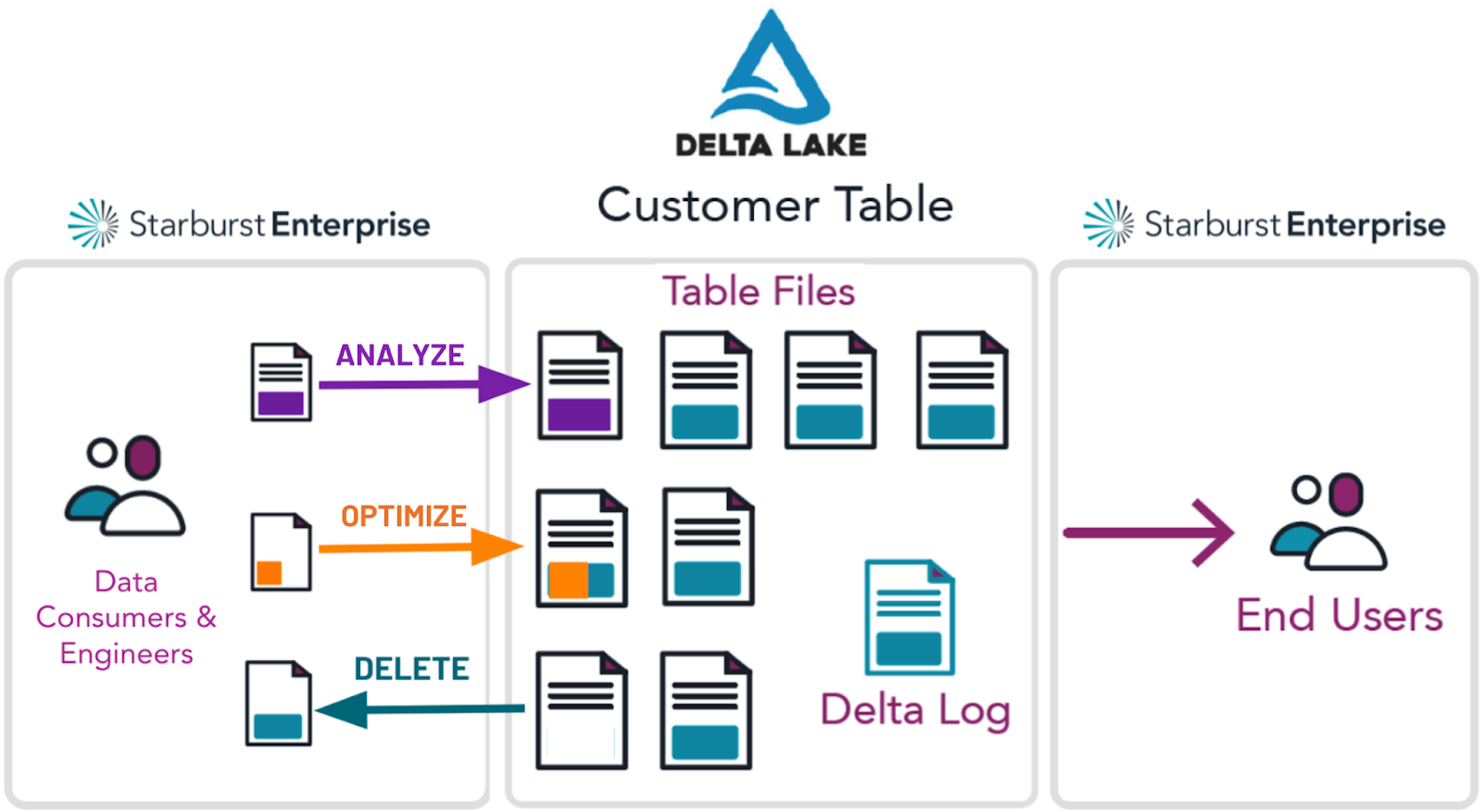
In previous releases, we added support for write operations, including INSERT, DELETE and UPDATE, to enable customers with the fine-grained ability to modify data directly in the lake. In this release, we’ve added support for native ANALYZE and pass-through OPTIMIZE capabilities for Delta Lake – two ways for customers to further improve query performance and time to insight.
Data lineage sync with Apache Atlas
![]()
Apache Atlas is a widely-adopted, open source data lineage tool with many commercial products built with Atlas as its core. Standardized data lineage and governance support allows data owners to control access while giving data consumers insight into the lineage of their data. Starburst’s Atlas integration allows sensitive data to be tracked as it is moved to ensure future access maintains the same security controls. Our governance support is significantly enhanced by integration with Apache Atlas, allowing customers to keep track of their data assets across multiple systems. This integration widens our scope of governance capabilities and support.
Seamless authentication

Starburst security gets even stronger this release. Starburst Enterprise can now authenticate with OIDC-compliant identity providers such as Okta, ADFS (Azure and on-premises), and pass-through OIDC identity to underlying data sources. We also integrate with AWS Identity & Access Management, or IAM, for MySQL, PostgreSQL and Elasticsearch. These updates allow customers to centralize authentication control for improved security and reduced operational overhead.
New and improved enterprise-only connectors
As more data products are created in the data mesh, it’s important to continue to add connectivity, preventing data silos. Starburst’s newest enterprise connector is DynamoDB, a fully-managed NoSQL database supporting key-value and document data structures offered by AWS. This connector enables users to perform analytics directly on DynamoDB without any data movement, reducing complexity and time to insight.

Previously, customers needed to extract data from DynamoDB and load into another database for SQL analytics. The Starburst DynamoDB connector is already released with a performance upgrade, supporting both dynamic filtering and Starburst Cached Views.
The Starburst Salesforce connector, now with simplified installation, also exposes Salesforce API usage and limits in system information. Because Salesforce is a SaaS application with rate limiting, users can only perform so many actions within a set amount of time before being throttled. The Starburst Salesforce connector provides insight into what was causing a user to hit their rate limit, helping the user to troubleshoot and avoid the behavior that led to being throttled in the first place.
![]()
The connector allows Starburst customers to benefit from running ad-hoc analytics directly on Salesforce without having to bulk export data to a separate database or data lake and run the risk of data becoming stale.
Other connector improvements include support for AWS Identity & Access Management (IAM) for MQL, PostgreSQL, and Elasticsearch. And thanks to our new Parquet reader (mentioned above), our existing Hive and Delta Lake connectors are more efficient at reading parquet files and can get end-users their answers faster. Additionally and already noted, the Delta Lake connector now has native ANALYZE and pass-through OPTIMIZE capabilities.
Multiple tab support and additional usage metrics for Starburst Insights
Starburst Insights provides a visual overview of important cluster metrics for all types of users, from platform administrators to data consumers. From the Starburst Insights interface, you can access cluster performance information from a selected date range and detailed query history, including single-query statistics and query plans. Starburst Insights includes Worksheet as a visual workbench to run ad hoc queries and explore configured data sources. New this release, is the support for multiple tabs to keep queries organized and allow multi-tasking. You can start a long-running query in one tab, and switch to another tab to run additional queries while your first query is executing. The query in the hidden tab continues to run, and displays results when it completes.

In addition to multiple tab support, we’ve also expanded visibility into usage metrics by extending date filters and data with additional dimensions, like node environment, version, and instance id. These capabilities allow more observability into cluster usage over time and tool for better cost estimation and transparency.
…
And these are just the highlights! The full release notes detailing all of the features can be viewed here. And if you’re interested in hearing more please register for our Starburst Enterprise’s Q3 (LTS 360-e) Release Webinar on Thursday, August 26th.
Want to see Starburst Enterprise in action? You can download it for free here!




