
The cloud revolution promised to help businesses operate with a level of efficiency and scale never before possible. Instead, after years of investment, companies are saddled with gussied up legacy technology that hasn’t done anything to actually help modernize their IT operations.
Today’s CIO is bombarded with buzzy new product categories that vendors swear are key to operating a “modern” business. But despite all the marketed innovation, most companies are still tethered to the past.
They’ve been tricked into believing that deploying anything with the words “cloud” or “as a service” equates to building a future-proof business. In reality, most of these new products are the same as the old, just in new wrapping paper.
And now, companies are finding the systems that were supposed to make everything easier have instead become an obstacle in their efforts to build a technology-first culture.
The so-called “modern” data stack isn’t modern. It’s just the data stack of decades ago moved to the cloud.
There are significant benefits to deploying in the cloud, of course. But the pivot underway across corporate America is no different from the architectural revamps of the past. For all its success, a cloud data warehouse is just a data warehouse deployed on cloud infrastructure rather than an on-prem appliance.
Otherwise, the products are effectively the same and share all the same problems that have plagued the industry for decades. Companies spend enormous amounts of capital and employee hours building and maintaining fragile ETL pipelines while trying to build a monolithic central data repository, only to find that their information is still scattered everywhere no matter how hard they try. Analysts and data scientists are still not getting all of the answers they need to move the business forward quickly and what was touted as a savior for the data platform team has turned into a new problem for already overworked data engineers.
It’s just a remake of an old movie we’ve all seen before.
New is not modern. We need something different. Something better.
The transformation ahead requires an altogether different approach. It requires tools that completely change the mindset that’s dominated IT operations for decades.
The “single source of truth” paradigm is dead. The truth is out there, but it doesn’t live in one place. To be truly competitive, businesses will increasingly need to be able to quickly analyze data from a wide variety of sources, combining new data with existing data to make faster and better decisions.
That’s where Starburst can help. Our platform doesn’t care what you’re running or where you’re running it. There’s no proprietary formats, so you’re not tethered to one vendor and you can build an architecture that stands the test of time. Most importantly, your data analysts can consume the data they need, including data they never had access to before.
That’s what the future of analytics requires. That’s a future that is truly modern.
If you’re a data rebel, watch now.
Free. Virtual. Global.
What is the modern data stack?
The modern data stack refers to the set of technologies and tools used to manage and analyze data in today’s data-driven businesses.
3 key components of the modern data stack
1. Data orchestration and data transformation with a data pipeline (ETL or ELT—reverse ETL)
The data pipeline is responsible for extracting data from its various sources, transforming it into a suitable format, and then loading it into an analytics-focused environment.
2. Data storage: data warehouse or data lake
The data warehouse or data lake serves as a centralized repository for the data collected from different sources through the data pipeline.
3. Analytics tool (Business intelligence and/or data visualization tool)
The analytics tool is the interface through which users interact with the data stored in the data warehouse or data lake to create business value. It could be a business intelligence (BI) tool, data visualization tool, or a combination of tools that enable users to query, analyze, and visualize the data on a dashboard.
The modern data stack’s architecture was designed to provide a seamless flow of data from source to analysis, ensuring that organizations can efficiently collect, store, process, and analyze vast amounts of data to extract meaningful insights and drive business growth.
What is the difference between traditional data stack and modern data stack?
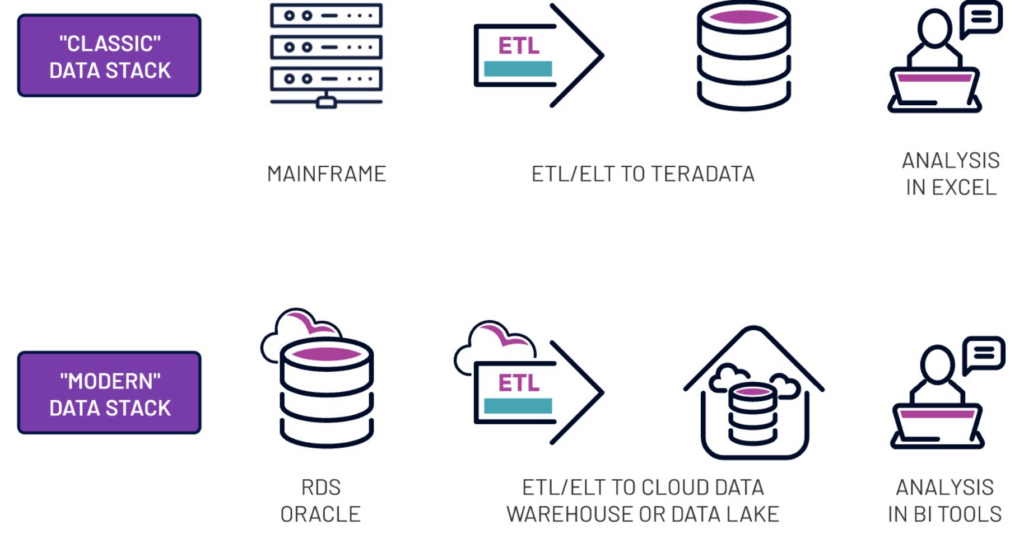
Despite new cloud-based and SaaS tools, the paradigm remains the same.
The traditional data stack operates on the fundamental idea that data must be moved into a centralized location, also known as a data warehouse to derive value from it. This approach involves having a dedicated database and enterprise ETL (Extract, Transform, Load) tool to extract data from various sources, transform it, and then load it into the centralized storage for analysis.
From an analytics tools perspective, the traditional data stack provides a basic data visualization and reporting capabilities for users to analyze the data stored from that centralized location. However, outside of these parameters, it might limit advanced data analytics capabilities.
And lastly, the traditional data stack usually operates on on-premises infrastructure, which can be costly to maintain and lacks the scalability and flexibility offered by cloud-based solutions.
However, is the modern data stack better because it’s a cloud-based data stack?
The modern data stack follows the principle of centralizing data for analysis. However, it goes a step further by leveraging cloud-based infrastructure and Software as a Service (SaaS) solutions. At first glance, this cloud-based approach offers greater scalability, flexibility, and cost-effectiveness compared to the on-premises infrastructure used in the traditional stack.
Sure, it incorporates better analytics tools. It also promises efficiency, scalability, and groundbreaking capabilities. However, upon closer examination, it becomes clear that this concept might not be as revolutionary as it seems.
The modern data stack embraces cloud-based technologies and SaaS offerings, enabling organizations to leverage the advantages of the cloud, such as elasticity, automatic scaling, data redundancy, and ease of integration with other cloud services. This cloud-native approach facilitates a more agile and efficient data management process.
The modern data stack is essentially a repackaged version of the data stacks used decades ago. The only significant difference is that it’s optimized for cloud environments. This cloud adaptation doesn’t automatically qualify it as modern, as the core architecture remains largely unchanged.
The modern data stack is reminiscent of data strategies from the past
In the early days, tools like Informatica and Teradata facilitated the process of extracting data from various sources and loading it into a centralized database. Today, we have names like FiveTran, Matillion, and Snowflake. Yet, the fundamental process of consolidating data remains consistent across the decades. The essence of the stack itself hasn’t undergone revolutionary changes; it has merely adapted to current technologies.
Is migration necessary for modernization?
A prevailing assumption within the modern data stack narrative is that migration is necessary for modernization. But modernization should be a process rather than a mere technological stack. The emphasis should be on evolving data strategies to align with changing business needs and technological advancements. In other words, modernization should be approached holistically, considering both the technology and the overall data strategy.
The power of data lakes
The modern data stack extends to the realm of data lakes and data warehouses. We’ve seen that data lakes offer advantages over traditional data warehouses, mainly due to their flexibility and compatibility with open data formats. While data warehouses can be limiting due to proprietary systems and vendor lock-in, data lakes empower organizations to work with formats like Iceberg, Hudi, and Delta. These formats promote future-proofing, enabling businesses to adapt and innovate over the long term.
Priceline’s ongoing journey towards data modernization
Priceline has embarked on what they term a “data mesh” transformation, aiming to leverage both streaming and historical datasets across different cloud and on-premises systems. While a significant part of this journey involves migrating data to Google Cloud, the focus is not solely on the technology stack. Instead, it’s about connecting various data sources and driving business outcomes.
One of Priceline’s use cases resonates with many attendees – personalization. By connecting historical and newer data, Priceline aims to enhance personalized experiences for its users. This use case underscores the importance of data connectivity and the potential for meaningful innovation when data strategies are adaptable and forward-looking.
In thinking about these flaws inherent in the modern data stack, we’ve started to instead wonder…What do you need for a true modern data stack?
What modern data stack tools you need
Picture stepping into a new company with a mission: create a data system that effortlessly unlocks business insights.
Your team is adept in SQL and keen on utilizing tools like Tableau for data-driven decision-making.
Operating within a contemporary cloud-based setup, where storage and compute can be decoupled, you’re free from hardware constraints.

The goal? A solution that caters to the Four S’s of data: speed, scalability, simplicity, and SQL.
By centering your architecture around these core principles, you’re poised to become a hero—empowering your data-savvy employees and paving the way for valuable business outcomes.
The future of the modern data stack
In pursuit of a streamlined and effective system that aligns with your objectives, simplicity takes the lead.
Enter Starburst Galaxy, a product designed to simplify your journey. With this solution, SQL operations are performed directly on your source data, no matter where it resides, eliminating the need for extensive data infrastructure efforts.
Building upon this foundation, layer in analytics tools, visualizations, and even machine learning capabilities. While this approach might not be a radical departure from the modern data stack, it does dramatically reduce the gap between data and actionable insights.
This optimization becomes particularly crucial in intricate and expanding organizations, delivering substantial efficiency gains that can redefine the path to success.
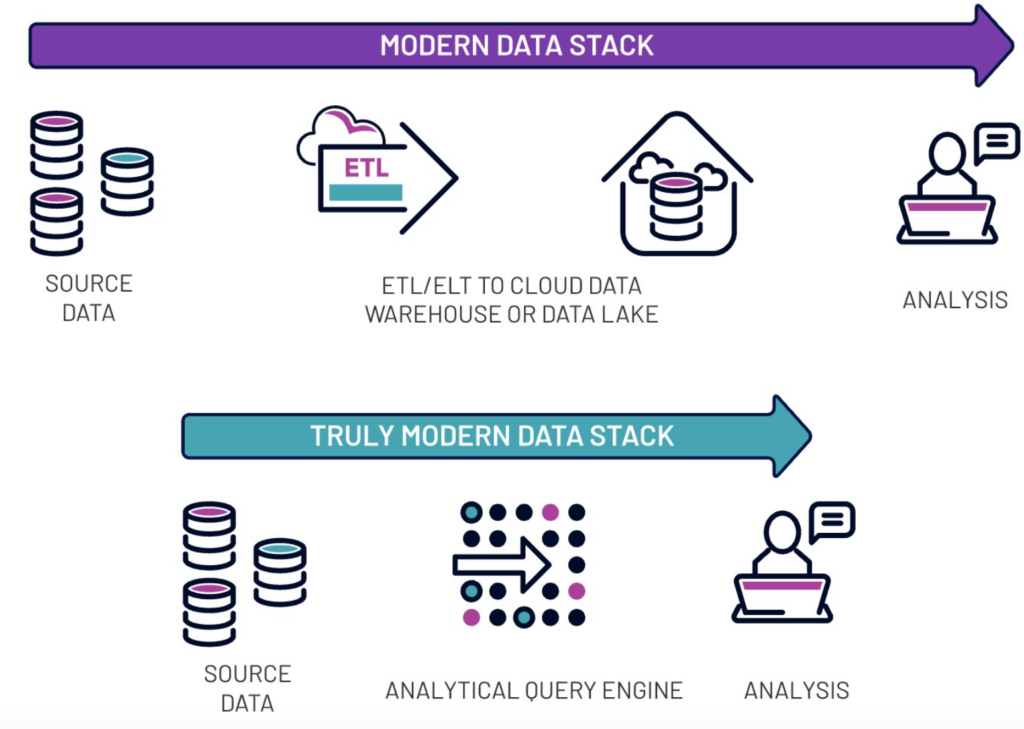
The truly modern data stack focuses on the four S’s, reduces latency and complexity, and is vendor-agnostic, ultimately shortening the path between the data and the business value derived from it.
This simplified approach also reaps a range of benefits. Say goodbye to extended batch processing times, thanks to the ability to use live or cached source data, effectively minimizing latency.
The advantages don’t end there – the streamlined setup fosters enhanced governance, including transparent data lineage, by minimizing intermediary tools and data stores. Fewer tools and storage prerequisites, coupled with a genuine separation of storage and compute resources, contribute to a more cost-effective and streamlined data ecosystem.
Embrace this journey toward data-driven excellence, where simplicity and efficiency converge in the realm of Starburst Galaxy.




