
Trino on ice I: A gentle introduction to Iceberg
Trino on ice II: In-place table evolution and cloud compatibility with Iceberg
Trino on ice III: Iceberg concurrency model, snapshots, and the Iceberg spec
Trino on ice IV: Deep dive into Iceberg internals

Welcome back to this blog series discussing the amazing features of Apache Iceberg. In the last two blog posts, we’ve covered a lot of cool feature improvements of Iceberg over the Hive model. I recommend you take a look at those if you haven’t yet. We introduced concepts and issues that table formats address. The next blogs will dive into some technical details to gain a better understanding around how some of these features are implemented. This blog closes up the overview of Iceberg features by discussing the concurrency model Iceberg uses to ensure data integrity, how to use snapshots via Trino, and the Iceberg Specification.
Concurrency Model
An issue with the hive model is the distinct locations where the metadata is stored and where the data files are stored. Having your data and metadata split up like this is a recipe for disaster when trying to apply updates to both services atomically.
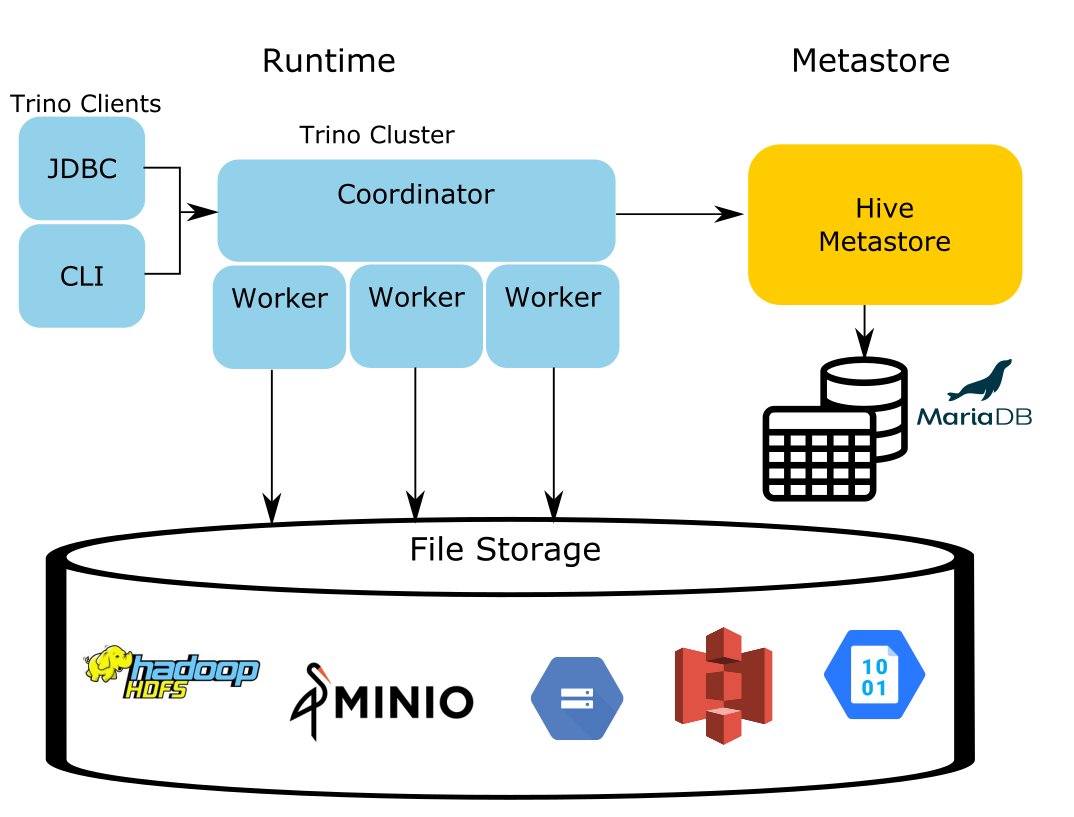
A very common problem with Hive is that if a writing process failed during insertion, many times you would find the data written to file storage, but the metastore writes failed to occur. Or conversely, the metastore writes were successful, but the data failed to finish writing to file storage due to a network or file IO failure. There’s a good Trino Community Broadcast episode that talks about a function in Trino that exists to resolve these issues by syncing the metastore and file storage. You can watch a simulation of this error on that episode.
Aside from having issues due to the split state in the system, there are many other issues that stem from the file system itself. In the case of HDFS, depending on the specific filesystem implementation you are using, you may have different atomicity guarantees for various file systems and their operations, such as creating, deleting, and renaming files and directories. HDFS isn’t the only troublemaker here. Other than Amazon S3’s recent announcement of strong consistency in their S3 service, most object storage systems only offer eventual consistency that may not show the latest files immediately after writes. Despite storage systems showing more progress towards offering better performance and guarantees, these systems still offer no reliable locking mechanism.
Iceberg addresses all of these issues in a multitude of ways. One of the primary ways Iceberg introduces transactional guarantees is by storing the metadata in the same datastore as the data itself. This simplifies handling commit failures down to rolling back on one system rather than trying to coordinate a rollback across two systems like in Hive. Writers will independently write their metadata and attempt to perform their operations, needing no coordination with other writers. The only time the writers will coordinate is when they attempt to perform a commit of their operations. In order to do a commit, they will perform a lock of the current snapshot record in a database. This concurrency model where writers eagerly do the work upfront is called optimistic concurrency control.
Currently in Trino, this method still uses the Hive metastore to perform the lock-and-swap operation necessary to coordinate the final commits. Iceberg creator, Ryan Blue, covers this lock-and-swap mechanism and how the metastore can be replaced with alternate locking methods. In the event that two writers attempt to commit at the same time, the writer that first acquires the lock successfully commits by swapping its snapshot as the current snapshot, while the second writer will retry to apply its changes again. The second writer should have no problem with this, assuming there are no conflicting changes between the two snapshots.
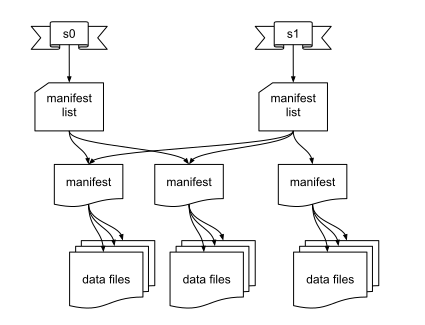
This works similarly to a git workflow where the main branch is the locked resource, and two developers try to commit their changes at the same time. The first developer’s changes may conflict with the second developer’s changes. The second developer is then forced to rebase or merge the first developer’s code with their changes before commiting to the main branch again. The same logic applies to merging data files. Currently, Iceberg clients use a copy-on-write mechanism that makes a new file out of the merged data in the next snapshot. This enables accurate time traveling and preserves previous split versions of the files. At the time of writing, upserts via MERGE INTO syntax are not supported in Trino, but this is in active development.
One of the great benefits of tracking each individual change that gets written to Iceberg is that you are given a view of the data at every point in time. This enables a really cool feature that I mentioned earlier called time travel.
Snapshots and Time Travel
To showcase snapshots, it’s best to go over a few examples drawing from the event table we created in the previous blog posts. This time we’ll only be working with the Iceberg table, as this capability is not available in Hive. Snapshots allow you to have an immutable set of your data at a given time. They are automatically created on every append or removal of data. One thing to note is that for now they do not store the state of your metadata.
Say that you have created your events table and inserted the 3 initial rows as we did previously. Let’s look at the data we get back and see how to check the existing snapshots in Trino:
| SELECT level, message
FROM iceberg.logging.events; |
Result:
| ERROR Double oh noes
WARN Maybeh oh noes? ERROR Oh noes |
To query the snapshots, all you need is to use the $ operator appended to the end of the table name, and add the hidden table, ‘snapshots’:
| SELECT snapshot_id, parent_id, operation
FROM iceberg.logging.“events$snapshots”; |
Result:
| |snapshot_id |parent_id |operation| |——————-|——————-|———| |7620328658793169607| |append | |2115743741823353537|7620328658793169607|append | |
Let’s take a look at the manifest list files that are associated with each snapshot ID. You can tell which file belongs to which snapshot based on the snapshot ID embedded in the filename:
| SELECT manifest_list
FROM iceberg.logging.“events$snapshots”; |
Result:
| s3a://iceberg/logging.db/events/metadata/snap-7620328658793169607-1-cc857d89-1c07-4087-bdbc-2144a814dae2.avro s3a://iceberg/logging.db/events/metadata/snap-2115743741823353537-1-4cb458be-7152-4e99-8db7-b2dda52c556c.avro |
Now, let’s insert another row to the table:
| INSERT INTO iceberg.logging.events VALUES ( ‘INFO’, timestamp ‘2021-04-02 00:00:11.1122222’, ‘It is all good’, ARRAY [‘Just updating you!’] ); |
Let’s check the snapshot table again:
| SELECT snapshot_id, parent_id, operation FROM iceberg.logging.“events$snapshots”; |
Result:
| |snapshot_id |parent_id |operation| |——————-|——————-|———| |7620328658793169607| |append | |2115743741823353537|7620328658793169607|append | |7030511368881343137|2115743741823353537|append | |
Let’s also verify that our row was added:
|
SELECT level, message |
Result:
| |ERROR|Oh noes | |INFO |It is all good | |ERROR|Double oh noes | |WARN |Maybeh oh noes?| |
Since Iceberg is already tracking the list of files added and removed at each snapshot, it would make sense that you can travel back and forth between these different views into the system, right? This concept is called time traveling. You need to specify which snapshot you would like to read from and you will see the view of the data at that timestamp. In Trino, you need to use the @ operator, followed by the snapshot you wish to read from:
| SELECT level, message FROM iceberg.logging.“events@2115743741823353537”; |
Result:
| |ERROR|Double oh noes | |WARN |Maybeh oh noes?| |ERROR|Oh noes | |
If you determine there is some issue with your data, you can always roll back to the previous state permanently as well. In Trino we have a function called rollback_to_snapshot to move the table state to another snapshot:
| CALL system.rollback_to_snapshot(‘logging’, ‘events’, 2115743741823353537); |
Now that we have rolled back, observe what happens when we query the events table with:
| SELECT level, message FROM iceberg.logging.events; |
Result:
| |ERROR|Double oh noes | |WARN |Maybeh oh noes?| |ERROR|Oh noes | |
Notice the INFO row is still missing even though we query the table without specifying a snapshot id. Now just because we rolled back, doesn’t mean we’ve lost the snapshot we just rolled back from. In fact, we can roll forward, or as I like to call it, back to the future! In Trino, you use the same function call but with a predecessor of the existing snapshot:
| CALL system.rollback_to_snapshot(‘logging’, ‘events’, 7030511368881343137) |
And now we should be able to query the table again and see the INFO row return:
| SELECT level, message FROM iceberg.logging.events; |
Result:
| |ERROR|Oh noes | |INFO |It is all good | |ERROR|Double oh noes | |WARN |Maybeh oh noes?| |
As expected, the INFO row returns when you roll back to the future.
Having snapshots not only provides you with a level of immutability that is key to the eventual consistency model, but gives you a rich set of features to version and move between different versions of your data like a git repository.
Iceberg Specification
Perhaps saving the best for last, the benefit of using Iceberg is the community that surrounds it, and the support you will receive. It can be daunting to have to choose a project that replaces something so core to your architecture. While Hive has so many drawbacks, one of the things keeping many companies locked in is the fear of the unknown. How do you know which table format to choose? Are there unknown data corruption issues that I’m about to take on? What if this doesn’t scale like it promises on the label? It is worth noting that alternative table formats are also emerging in this space and we encourage you to investigate these for your own use cases. When sitting down with Iceberg creator, Ryan Blue, to discuss what he thought makes Iceberg stand out in comparison to other table formats, he claims the community’s greatest strength is their ability to look forward. They intentionally broke compatibility with Hive to enable them to provide a richer level of features. Unlike Hive, the Iceberg project explained their thinking in a spec.
The strongest argument I can see for Iceberg is that it has a specification. This is something that has largely been missing from Hive and shows a real maturity in how the Iceberg community has approached the issue. On the Trino project, we think standards are important. We adhere to many of them ourselves, such as the ANSI SQL syntax, and exposing the client through a JDBC connection. By creating a standard around this, you’re no longer tied to any particular technology, not even Iceberg itself. You are adhering to a standard that will hopefully become the de facto standard over a decade or two, much like Hive did. Having the standard in clear writing invites multiple communities to the table and brings even more use cases. Doing so, improves the standards and therefore the technologies that implement them.
The previous three blog posts of this series covered the features and massive benefits from using this novel table format. The following post will dive deeper and discuss more about how Iceberg achieves some of this functionality, with an overview into some of the internals and metadata layouts. In the meantime, feel free to try Trino on Ice(berg).




