
The idea of a single source of truth has been around since the beginning of big data. However, over the years, through the data warehouse, the data lake, and the data lakehouse, this concept has been continually sought after, with very limited success. Ultimately, the distribution and volume of data in today’s modern enterprise is so complex, the reality of achieving a true single source of truth is far more myth than attainable milestone. ETL has become the modern day Sisyphus – moving data from database to database, location to location, only to repeat the process over again at a larger scale. While no one disputes the advancements we’ve made, unfortunately, the boulder keeps falling back down the hill with regards to data management and accessibility. Because many organizations use multiple databases and storage systems, we see a lot of customers take on federation as a use case. Instead of trying to achieve this single source of truth, it’s often better to accept that the best mode of operation is to distribute your data across multiple sources, and, instead, have a single source of access. By keeping your data where it lives, time to insights improve, it is less expensive, and more secure. And, your data teams can spend less time copying and moving data, what could be better than that.

At the onset of the data warehouse, clean data was able to be stored in one place. Different from a database, a data warehouse compiles data from multiple sources or multiple databases, organizes it, and stores it in a manner that is ready to be analyzed. Although it is a well-established form of data management, it doesn’t provide the agility needed for today’s competitive market because it doesn’t account for various forms of data that might live in other repositories. Furthermore, because a data warehouse only supports processed data, if there is a business question that requires that data for analysis, it needs to be processed before it can become actionable, creating delays. Therefore, there is too much time spent copying data in order to fit inside this monolithic approach. Organizations continue to waste unnecessary time and money to have some data not be easily accessible. We’ve made progress, but we still move.
The data lake provided more optionality in terms of the types of data that could be stored as it can store unprocessed data. However, it has never sufficiently been optimized for data queries. Furthermore, limitations exist on the variety and volume of data that you dump into a data lake for, most likely, an undefined future use. This makes the data lake another potentially costly option. So we end up either having to move data out of the data lake to be analyzed, or move data into the data lake for unknown future use. Again, progress in some areas, but we’re still moving data.
The data lakehouse seems to be an option to data management problems as it combines some of the best of the data warehouse and the data lake. It supports both processed data and raw data. It also has low cloud storage costs while still providing advanced querying capabilities. Processed data can be organized into charts and tables while still allowing for raw data or other newer forms of data to also be stored in one central location. But can we really achieve all the analytic benefits of data warehouse and storage benefits of a data lake? Or will it soon be obvious once again the “solution” to data management falls below the standards envisioned with the myth of a single source of truth? Time will tell. For now, we’re faced with the same inevitable problems. None of these repository options can scale to the volume of data and the variety of data sources that organizations have today, and, more importantly, scale to the complexity of enterprises of tomorrow. Because let’s face it, we’ve seen incremental progress like this before. And the boulder unfortunately doesn’t reach the peak.
What if we stopped pushing boulders uphill? What if we could just leave the data where it is? Or better yet, ETL some data one last time to cheaper storage? What if, instead of a single source of truth, we had a single point of access to all data?
Enter Starburst. The single point of access for your data, no matter where it lives. Our solution shifts the industry from a monolithic, rigid, stuck-in-time single source of truth to a federated, flexible, real-time single source of intelligence. As a result of this new approach, companies can see the new possibilities for analytics, driving more productivity, and better time to insight. Store your data however you’d like. We unlock access wherever it lives so businesses can quickly analyze it and take decisive action.
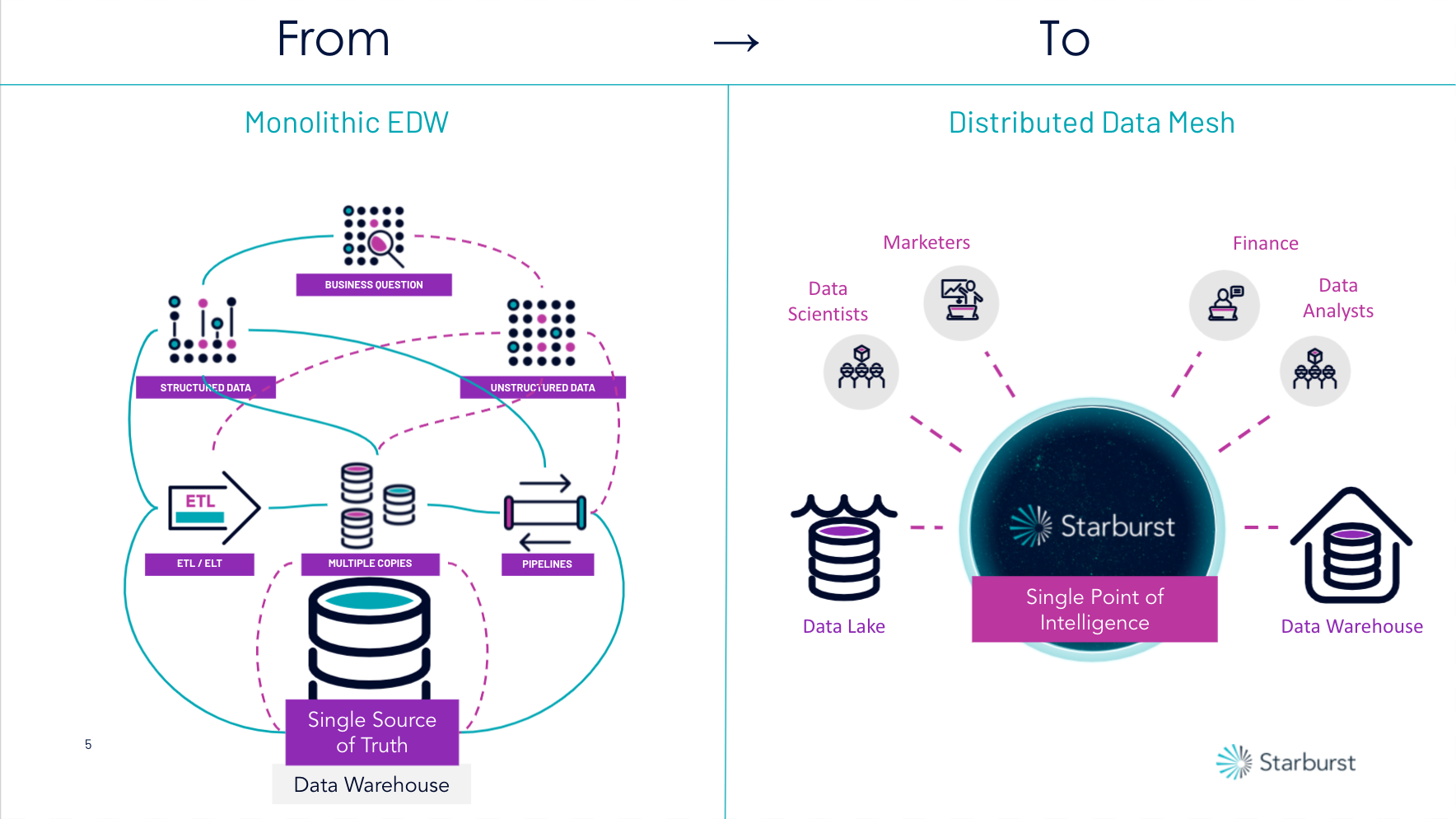
This means no more cubes, extracts, or aggregation tables. Starburst delivers a data consumption layer that provides global security and business logic. By adopting a distributed data approach, you can get the most out of your data. Furthermore, data teams are empowered with the ability to create data domains, granting access across department, region, and locality. Data Mesh architecture embraces distributed data and technologies, with the notion of establishing data products and data domains.
With over 40+ out of the box connectors to common data sources, Starburst allows you to see the invisible and achieve the impossible with your data analytics. By leveraging ANSI-SQL, at MPP scale, we drive fast queries across your distributed data to give you fast, accurate, real-time decisions. And, by separating compute and storage, we can greatly reduce costs.
Starburst flips the data analytics centralization model on its head and embraces modern Data Mesh architecture, and gives the enterprise the freedom to easily ask questions of all data, so leaders can make better data-driven decisions with speed and confidence.
I promise there won’t be any more Sisphyean ETL by embracing distributed data.
For more information, read our solution brief here.




