
The typical big data infrastructure is a Frankenstein’s monster of legacy hardware, cloud connections, and storage environments. Data exists in different silos, in every location imaginable. This complicates data accessibility, which hinders analysts productivity. Analysts shouldn’t have to be concerned with where their data is, to where it’s being migrated, or that their company has decided to begin their shift to the cloud. They just want fast access.
As big data stacks continue to evolve and data sources come and go, how will data users be able to keep moving the chains despite IT disruption? The answer to this question lies in what we call a ‘consumption layer’ (also known as abstraction layer, semantic layer, query fabric, etc).
What is a consumption layer
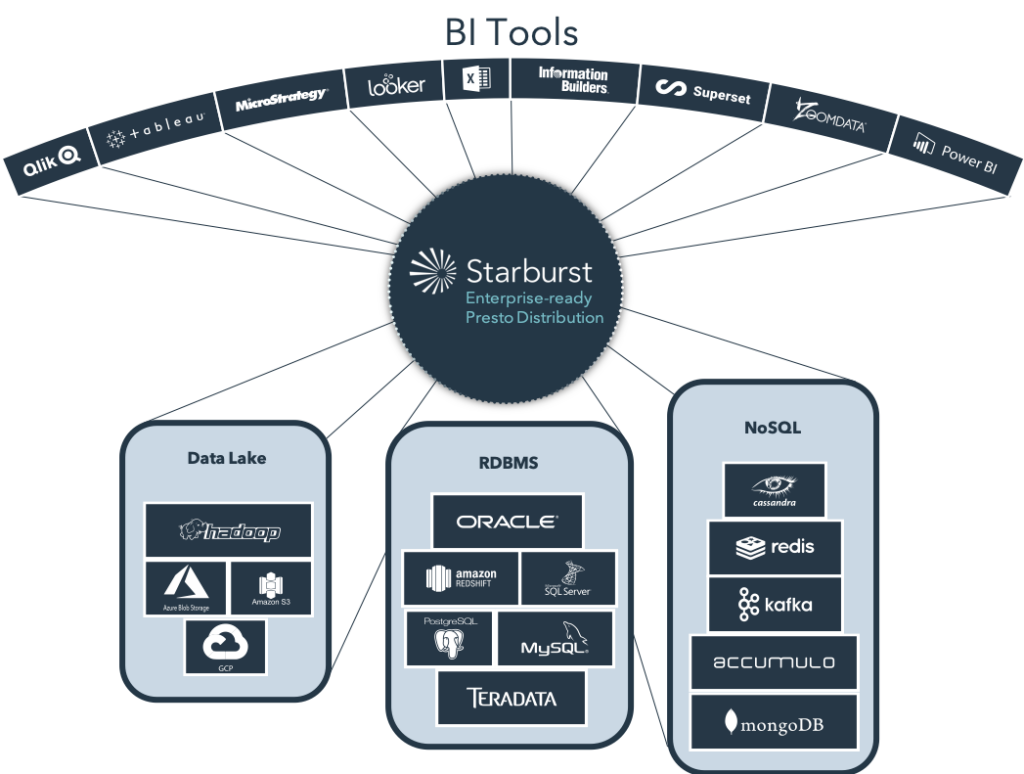
Simply put, a consumption layer is a tool that sits between your data users and data sources. This layer takes a SQL query as input (from a BI tool, CLI, ODBC/JDBC, etc.) and handles the execution of that query as fast as possible, querying the required data sources and even joining data across sources when needed. Ideally, this layer will be highly scalable and MPP in design.
With this design, your analysts can access data anywhere, without any ETL or data movement required. Even better, they don’t even have to know if the data is in Teradata, Hadoop, or S3. They just get results, which is all they really care about.
The benefits of a consumption layer
A consumption layer immediately creates multiple benefits for the organization.
Primarily, it insulates users from any data migrations and removes a lot of the risks inherent in data movements. This becomes increasingly important as data strategies evolve and organizations upgrade databases or begin the shift to the cloud.
Instead of undergoing one huge data migration effort (which is an extremely painful experience that can take months or even years to complete), database administrators can move data into (or out of) any of their data sources/new data sources at their convenience, without disrupting end users’ operations.
A consumption layer also relieves network architects of much of the complexity associated with building and maintaining a solutions stack. Instead of having to plan for years into the future, architects have the power to add and remove data sources as they see fit, while still taking advantage of the existing infrastructure that required a lot of time and money to build.
All-in-all, a consumption layer is able to keep front-end users blissfully in the dark about back-end operations, because it can access data from any source in any location. Starburst Enterprise was created with this ability in mind. For SQL queries, neither Starburst Enterprise, nor the analyst using it, cares about data’s format and location – they both just want to crunch a lot of numbers and get results fast. Given that cloud migrations will continue to increase, Starburst Enterprise is ideal for making sure end users can remain productive while IT can make this move at their own pace.
Beating vendor lock-in
Unfortunately, most of us are all too familiar with this story…Database vendors want you to put as much of your data, if not all of it, into their data store, often in a proprietary data format. They also want to lock you in for a few three-year cycles, sharply limiting your agility and freedom along the way. If your data grows, so will your charges, and that’s money that could be better spent elsewhere. It’s one of the biggest risks you face when building your big data platform.
Using Starburst Enterprise as your consumption layer immediately solves this dilemma. Since Starburst Enterprise can connect to almost any data source, you effectively commoditize your storage, allowing you to select the solutions that are right for your business without fear of vendor lock-in.
Access data quickly with your existing investments
With a proper consumption layer like Starburst Enterprise, organizations can continue to benefit from the infrastructure they have in place today, without worrying about all the problems that come with vendor lock-in. Users won’t be negatively affected by data movement or its format.
IT teams can identify and deploy the optimal combination of technologies that provides the best value and ROI to take advantage of the different strengths within each platform. IT teams can also properly prepare and execute their move to the cloud over time.
Starburst Data is neither a database vendor nor a storage company. As a result, Starburst Enterprise is not concerned about data’s home or format. It just wants to make your analytics as fast and easy as possible.
If you’d like to learn more about future-proofing your architecture and maintaining optionality, be sure to read ‘The Power of Optionality in Enterprise Data Architectures’.




