
Starburst Enterprise 2022 Q1 Product Release
The Starburst Enterprise 2022 Q1 release (370-e LTS), provides Starburst customers with new capabilities alongside more advanced connectivity, improved performance, and enhanced security. As always, this major release combines features that have been contributed back to the open source Trino project, as well as being curated for Starburst Enterprise customers. To experience this latest release first hand, please visit our download site.
Some notable features for this release include:
Restyled Starburst Enterprise UI
The Starburst Enterprise UI has been updated for simplicity, with an intuitive sidebar menu for better usability and management.
Additionally, we’ve added a space for managing our new built-in access controls with ‘Roles and Privileges (more on that below, too!)
Starburst data products
While certainly central to a data mesh journey, that concept of treating ‘data as a product’ benefits and enables numerous analytic strategies. However, the process of creating and managing data as a product has been historically complex. What makes modern technologies such as Starburst so appealing, is they obviate the need to move data around nearly as much. By leaving data at its source, or closer to the source, analytics can get closer to real-time, and with less infrastructure to worry about.
Starburst data products, in production availability, is a module in the Starburst Enterprise platform which allows data producers to create and maintain data products. This same platform can be used by data consumers to discover and understand and use these data products. Starburst makes it easy to produce, share, and consume data products using the built-in workflows and query editor.

In a world where you have thousands of data products, it is going to be much easier and cheaper to operate data products as queries. This way, you aren’t required to store the data independently, and you don’t need a team of engineers or architects to manage release cycles or data duplication across each product.
Let’s be clear, this isn’t just a data catalog. Our customers are building the data products themselves; performing the queries and creating the views, not merely showing them in a UI. Views, or materialized views, offer a saved view of cached data that you can access faster and can improve query speed. Starburst data products blends the power of Starburst’s analytical query engine with the discoverability and user-friendly capabilities of a data catalog. All this with built-in access controls and security integrations with governance tools to provide a secure, high-performance solution.

Starburst’s data products interface is targeted at the interactions between data producers and consumers, so they can use their common language, SQL, to define and consume data products. A larger fraction of their time can now be spent on creating and refining business insights and strategy based on reliable data.
We continue to see a rapid rise in demand from companies that want to build and share data products. Treating data as a first-class product drives domain owners to deliver high value and high-quality data for analysis by a wide range of consumers across the organization. Starburst data products can benefit any analytics journey, large or small, on-premises or multiple clouds, in a warehouse or a lake. And federates across all of them.
Built-in access control
We’re also thrilled to introduce a built-in role-based access control (RBAC) system, in public preview, that is integrated within Starburst Enterprise. The RBAC capabilities makes it easy to configure any user’s correct access rights to catalogs and to individual schemas, and tables. If your security needs require more granular control, you can restrict or allow access to specific columns within a table, or to functions, stored procedures, or session properties.

Built-in access control is now one of many security features Starburst supports. From authorization, to encryption, to 3rd-party and partner integrations, we ensure we meet you where your data is, with the security optionality that best fits your needs. With built-in access control, users can easily create groups of users based on their specific role and the privileges they are allowed directly from the Starburst UI.

The result for our customers is less administrative overhead, supportability improvements, and more seamless security experience.
Improved CPU utilization
Continuously improving performance is commitment from our product and engineering teams. This release we’re proud to have improved CPU utilization so our users can get more power out of their existing infrastructure. This means better scheduling and execution decisions to ensure there are fewer cases where query execution is blocked.
The results of focusing our efforts on increasing CPU utilization and reducing query wall time were reflected in our internal benchmark.
- 20% reduction in wall time for TPC-H partitioned data
- Customers should be able to expect an average reduction of 13% in wall time
- We have seen improvements as high as 50% for TPC-H query 12 on partitioned data
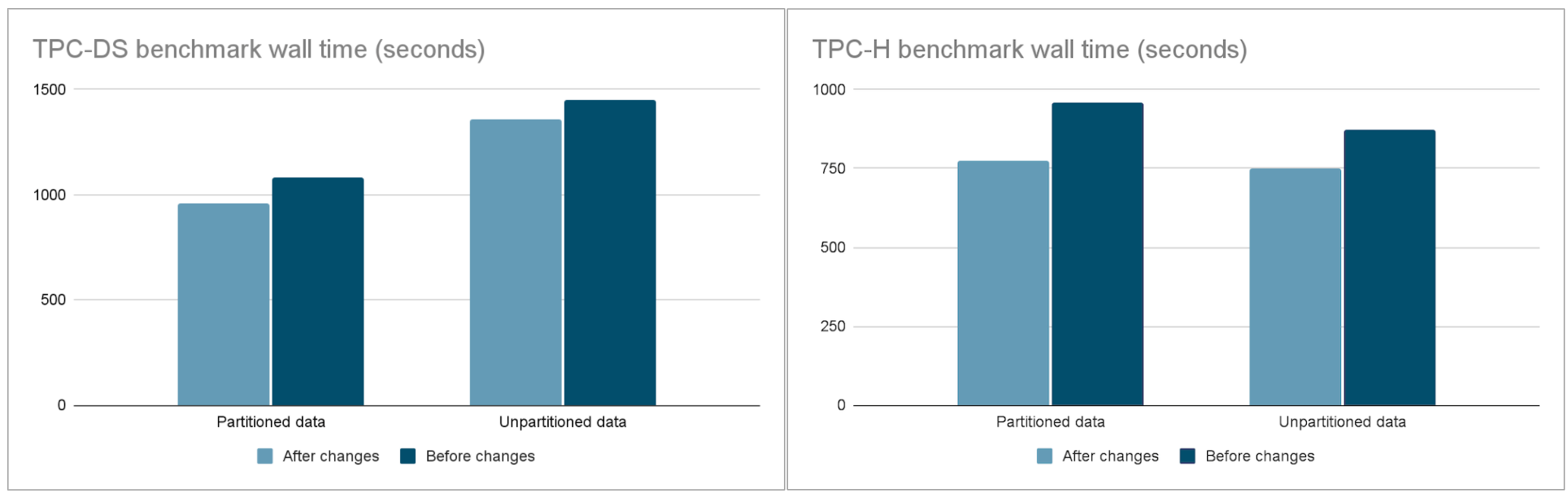
The benchmark results were obtained by running the TPC-H and TPC-DS benchmarks with one coordinator and six worker nodes. The data was queried by the Hive connector with partitioned and unpartitioned data at 1TB scale.
Connector Improvements
Starburst’s power to provide advanced analytics on a data lake has been extended by adding support for our accelerated Parquet reader to Iceberg. The average performance improvement is 15% (TCP-DS) and 20% (TPC-H). Speed goes hand and hand with the ability to transform data, as support for INSERT workloads on Iceberg is also included in this release.


The Starburst Delta Lake connector is again enhanced with native data management OPTIMIZE support. We’ve also improved SELECT performance on partitioned tables by creating more optimal file sizes during the table optimization, and improved query planning when filtering on a partitioned column.

There have also been general improvements made to our existing enterprise connectors for Google BigQuery, SingleStore, MySQL, Oracle, Postgres, Redshift, SQL Server, Teradata, Cassandra, Clickhouse, Apache Druid, Amazon DynamoDB, Kafka, MongoDB, Apache Phoenix, and Apache Pinot.
And these are just the highlights! The full release notes detailing all of the features can be viewed here. And if you’re interested in hearing more please register for our Starburst Enterprise’s 2022 Q1 Release Webinar on Thursday, February 24th.
Want to see Starburst Enterprise in action? You can download it for free here!




