
The key to success for any company is deriving business value from data in a robust, scalable, and timely fashion. A huge part of a successful data strategy is treating data as a product, as evidenced by the huge interest and buzz around Data Mesh. Starburst’s new Data Products user experience is the ideal platform for creating and consuming data products in order to assist in the implementation of a Data Mesh.
The Centralization Bottleneck
It’s 2022 and everybody knows that data is a key differentiating factor for successful businesses. But that said, there is often a dichotomy around how data is valued at companies: On the one hand, data should be valued at all levels, and that’s often articulated as the quest to be “data-driven.” On the other hand, it can be hard to get buy-in, and companies are often resistant to actually investing in data initiatives that they’re not confident will ultimately work. This contradiction often manifests itself as an effort to funnel all data to a central data team that is tasked with collecting, understanding, and curating data from all corners of the organization. This is, frankly, a herculean effort that only gets more complex at scale.
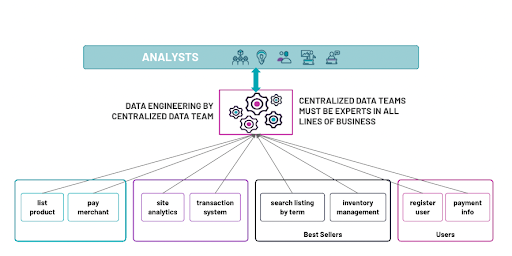
It helps to remember that the ultimate goal is to use data to make strategic decisions. Therefore, it is necessary to rethink how we have traditionally done things. The benefits of data-driven decision-making are clear, starting with increased transparency, consistency, and accountability for strategic decisions. Building a strategy with data can increase customer retention, help you enter new markets, and reduce overall costs.
Data Mesh: Embracing Decentralization
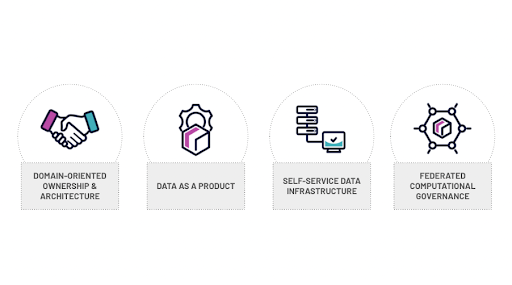
Data Mesh seeks to solve this bottleneck by embracing a decentralized data management paradigm, both from architectural and organizational aspects. Data Mesh has four pillars: domain-oriented ownership and architecture, data as a product, self-service data infrastructure, and federated computational governance.
The focus in a Data Mesh is on letting the subject matter experts with the most knowledge about the data use it to create data products, which are produced by the domains themselves, the data producers. There’s no more central data engineering team creating a bottleneck for all data curation because it happens instead within the domains. Therefore, you need to adjust responsibilities and product ownership to reflect the fact that data is a full-fledged, first-class product that these teams are accountable for. In the end, this will serve to remove the bottlenecks and improve the flow of data from the source to the consumer.
Treating Data as a Product
Domain-driven design and data as a product go hand in hand because they espouse the idea of keeping data as the responsibility of the teams which produce the data and control its source. Data is a first-class citizen and a product of the domain. The teams then need to be aware and aligned with the downstream consumers of their data and develop data products that ultimately drive business decisions and value. In a Data Mesh, each domain is responsible for ingesting, processing, and serving its data products to downstream consumers. What this means organizationally is that data engineering and software engineering become tightly aligned, and ideally part of the same functional team, so they can work with a data product owner to produce high-quality, curated data products.
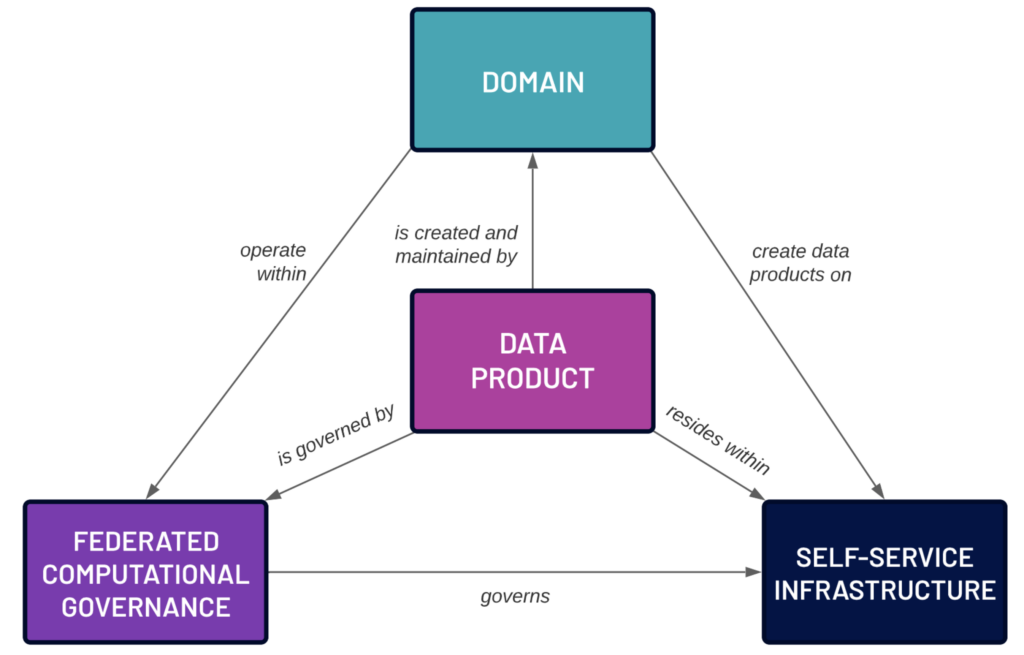
Data products are the heart of the Data Mesh. A data product can range from a simple, cleansed list of transactions to a highly curated and complex group of datasets. In practice, data products are frequently far more complex, and can even be used to produce other data products within the same or different domains. For example, user profile information can be combined with product information to drive marketing efforts, which are in turn used to create a customer value data product.
Starburst Data Products
Starburst recently introduced Data Products, our one-stop-shop for creating, maintaining, and using data products. From a Starburst perspective, data products are the result of our analytical queries that connect to multiple data sources, aggregating and analyzing multiple data sources to create uniquely valuable datasets. This approach has tremendous advantages:
- In a world where you have thousands of Data Products, it is going to be much easier and cheaper to operate data products as queries.
- You aren’t required to store the data independently
- You don’t need a team of engineers or architects to manage release cycles or data duplication across each product.
These are huge advantages and allow you to get up and running with Data Products in a Starburst environment quickly and without a huge infrastructure buy-in.
Our unique user experience allows data producers and data engineers to both curate data and define the relevant metadata to provide all of the context an end-user needs to use this data product. Additional important metadata such as usage metrics, bookmarks, commentary, sample queries, and more are automatically available as part of the data product.
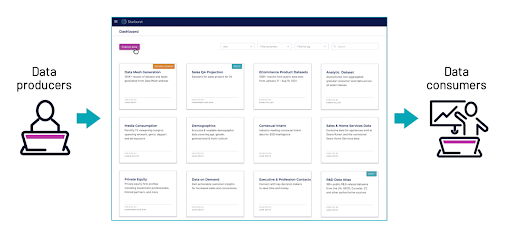
The beauty of using the Starburst Enterprise engine here is that this source data can be anywhere and we can easily connect to it, regardless of location — on-prem, in the cloud, or both. Particularly with Starburst Galaxy, we provide a fast and straightforward way to query data across multiple data sources without having to build complex pipelines. This forms the backbone of a self-service data infrastructure.
Interested in learning more?
Watch this on-demand webinar on democratizing disparate data with Starburst Data Products




