
Most companies want to follow good security practices. With the number of security breaches coming out daily, it almost feels like a matter of time before your company finds its name on the headlines and has to do some apologizing and damage control. Storing sensitive data in plaintext can easily result in information leaks which can occur in many unintended ways. Anyone with access to the configuration file can see the sensitive data. Users may also copy these configuration files or share via unencrypted email. Sensitive data may also accidentally be exposed such as on a screen share session.
Trino configuration files are commonly kept in source control systems such as git. It is recommended that sensitive data such as passwords are never committed to source control. An example of sensitive information that may be stored in a Trino configuration file is storing a username and password when configuring a RDBMS catalog.
Trino supports using environment variables as values for any configuration property. In the documentation, these are referred to as secrets. For example, if we were configuring a PostgreSQL catalog in Trino, we would have a etc/catalog/postgres.properties file with:
connector.name=postgresql
connection-url=jdbc:postgresql://hostname:5432/dbname
connection-user=${ENV:PG_USER}
connection-password=${ENV:PG_PASSWORD}Once the environment variables PG_USER and PG_PASSWORD exist, the catalog will be configured correctly.
The question then becomes: how and when do we set the values for these environment variables?
Let’s assume we are installing Trino using the RPM package. Recently, a change was made so any environment variables you want Trino to be able to read can be defined in CONFIG_ENV. CONFIG_ENV is typically set by a startup script before a service/process is started. When Trino is installed from an RPM, a file named /etc/trino/env.sh will be present and will be sourced whenever the Trino service is started.
Thus, once we put our secrets in CONFIG_ENV correctly in the /etc/trino/env.sh file, we’ll be good. Many products exist for managing external secrets such as Google’s Secret Manager, AWS Secrets Manager, and Hashicorp Vault to name a few. With enterprise customers deploying Trino in an on-premise environment, we have made API calls to systems deployed internally for managing secrets such as Hashicorp Vault to retrieve secrets when Trino is starting.
For example, let’s say we are using the AWS Secrets Manager for storing our sensitive data that we would like to use in our Trino configuration files. The AWS Secrets Manager can be accessed through the AWS Console just like any other service.
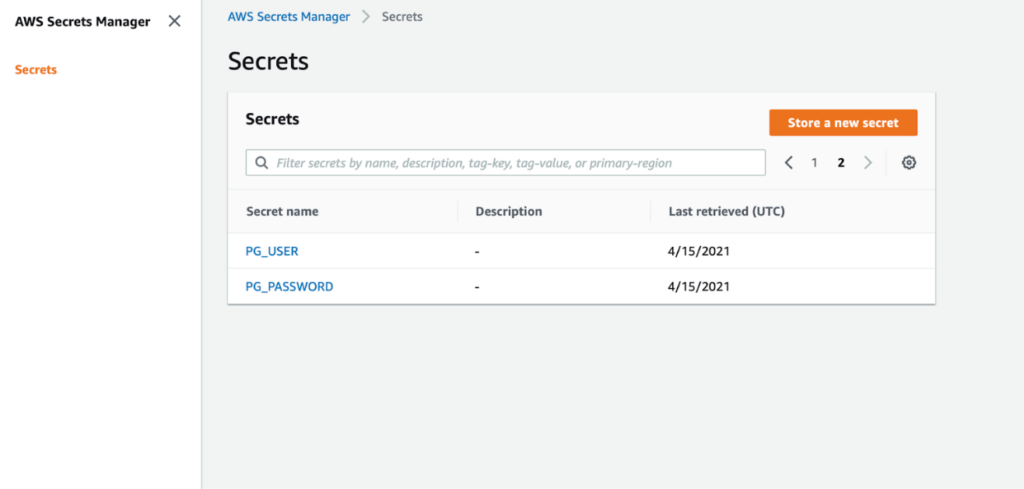
The AWS Secrets Manager interface is quite simple. You can view all existing secrets and there is a button to create new ones. That is about it!
As with most things in AWS, anything you can do through the web console can be achieved from the CLI. So let’s imagine we created some secrets in AWS Secrets Manager using the CLI like:
aws secretsmanager create-secret --name PG_USER --secret-string USERNAMEaws secretsmanager create-secret –name PG_PASSWORD –secret-string PASSWORD
You can see these secrets through the AWS console as well:
To retrieve these secrets during Trino startup and ensure they are available as environment variables, we could put the following in the /etc/trino/env.sh file:
CONFIG_ENV[PG_USER]=$(aws secretsmanager get-secret-value --secret-id PG_USER --output text --query SecretString)
CONFIG_ENV[PG_PASSWORD]=$(aws secretsmanager get-secret-value --secret-id PG_PASSWORD --output text --query SecretString)
If you are deploying Trino with kubernetes, then you can use the feature kubernetes provides of using secrets as environment variables. If you are a Starburst customer, the helm charts provided by Starburst for deploying Trino have support for referencing external secrets created in a system such as AWS Secrets Manager. Please see our documentation for more information and examples.
I hope this brings awareness to how simple it is to manage secrets for your Trino cluster. Doing this helps you and your company from inadvertently exposing sensitive information which could lead to attacks or data breaches.




