
If you haven’t heard of Trino before, it is a query engine that speaks the language of many genres of databases. As such, Trino is commonly used to provide fast ad-hoc queries across heterogeneous data sources. Trino’s initial use case was built around replacing the Hive runtime engine to allow for faster querying of Big Data warehouses and data lakes. This may be the first time you have heard of Trino, but you’ve likely heard of the project from which it was “forklifted”, Presto. If you want to learn more about why the creators of Presto now work on Trino (formerly PrestoSQL) you can read the renaming blog that they produced earlier this year. Before you commit too much to this blog, I’d like to let you know why you should even care about Trino.

Trino’s mascot: Commander Bun Bun
So what is Trino anyways?
The first thing I like to make sure people know about when discussing Trino is that it is a SQL query engine, but not a SQL database. What does that mean? Traditional databases typically consist of a query engine and a storage engine. Trino is just a query engine and does not store data. Instead Trino interacts with various databases that store their own data in their own formats. Trino parses and analyzes the SQL query you pass in, creates and optimizes a query execution plan that includes the data sources, and then schedules worker nodes that are able to intelligently query the underlying databases they connect to.
I say intelligently, specifically talking about pushdown queries. That’s right, the most intelligent thing for Trino to do is to avoid making more work for itself, and try to offload that work to the underlying database. This makes sense as the underlying databases generally have special indexes and data that are stored in a specific format to optimize the read time. It would be silly of Trino to ignore all of that optimized reading capability and do a linear scan of all the data to run the query itself. The goal in most optimizations for Trino is to push down the query to the database and only get back the smallest amount of data needed to join with another dataset from another database, do some further Trino specific processing, or simply return as the correct result set for the query.

Query all the things
So I still have not really answered your question of why you should care about Trino. The short answer is, Trino acts as a single access point to query all the things. Yup. Oh and it’s super fast at ad-hoc queries over various data sources including data lakes (e.g. Iceberg/Databricks) or data warehouses (e.g. Hive/Snowflake). It has a connector architecture that allows it to speak the language of a whole bunch of databases. If you have a special use case, you can write your own connector that abstracts any database or service away to just be another table in Trino’s domain. Pretty cool right? But that’s actually rarely needed because the most common databases already have a connector written for them. If not, more connectors are getting added by Trino’s open source community every few months.
To make the benefits of running federated queries a bit more tangible, I will present an example. Trino brings users the ability to map standardized ANSI SQL query to query databases that have a custom query DSL like Elasticsearch. With Trino it’s incredibly simple to set up an Elasticsearch catalog and start running SQL queries on it. If that doesn’t blow your mind, let me explain why that’s so powerful.
Imagine you have five different data stores, each with their own independent query language. Your data science or analyst team just wants access to these data stores. It would take a ridiculous amount of time for them to have to go to each data system individually, look up the different commands to pull data out of each one, and dump the data into one location and clean it up so that they can actually run meaningful queries. With Trino all they need to use is SQL to access them through Trino. Also, it doesn’t just stop at accessing the data, your data science team is also able to join data across tables of different databases like a search engine like Elasticsearch with an operational database like MySQL. Further, using Trino even enables joining data sources with themselves where joins are not supported, like in Elasticsearch and MongoDB. Did it happen yet? Is your mind blown?

Getting Started with Trino
So what is required to give Trino a test drive? Relative to many open source database projects, Trino is one of the more simple projects to install, but this still doesn’t mean it is easy. An important element to a successful project is how it adapts to newer users and expands capability for growth and adoption. This really pushes the importance of making sure that there are multiple avenues of entry into using a product all of which have varying levels of difficulty, cost, customizability, interoperability, and scalability. As you increase in the level of customizability, interoperability, and scalability, you will generally see an increase in difficulty or cost and vice versa. Luckily, when you are starting out, you just really need to play with Trino.
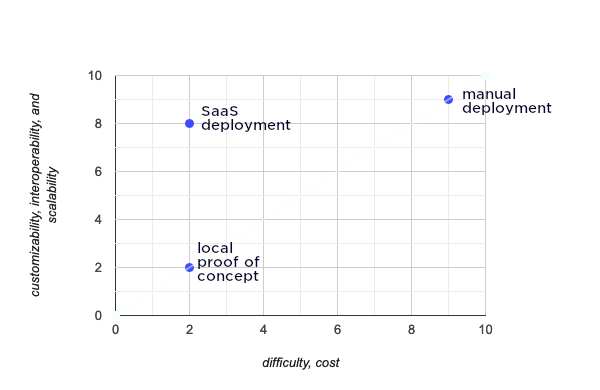
The low cost and low difficulty way to try out Trino is to use Docker containers. The nice thing about these containers is that you don’t have to really know anything about the installation process of Trino to play around with Trino. While many enjoy poking around documentation and working with Trino to get it set up, it may not be for all. I certainly have my days where I prefer a nice chill CLI sesh, and other days where I just need to opt out. If you want to skip to the Easy Button way to deploy Trino (hint, it’s the SaaS deployment) then skip the next few sections here.
Using Trino With Docker
Trino ships with a Docker image that does a lot of the setup necessary for Trino to run. Outside of simply running a docker container, there are a few things that need to happen for setup. First, in order to use a database like MySQL, we actually need to run a MySQL container as well using the official mysql image. There is a trino-getting-started repository that contains a lot of the setup needed for using Trino on your own computer or setting it up on a test server as a proof of concept. You can actually run a query before learning the specifics of how this compose file works.Before you run the query, you will need to run the mysql and trino-coordinator instances. To do this, navigate to the root directory that contains the docker-compose.yml and the etc/ directory and run:
| docker-compose up -d |
Running your first query!
Your first query will actually be to generate data from the tpch catalog and then query the data that was loaded into mysql catalog.
| CREATE TABLE mysql.tiny.customer AS SELECT * FROM tpch.tiny.customer; SELECT custkey, name, nationkey, phone FROM mysql.tiny.customer LIMIT 5; |
The output should look like this.
| |custkey|name |nationkey|phone | |——-|——————|———|—————| |751 |Customer#000000751|0 |10-658-550-2257| |752 |Customer#000000752|8 |18-924-993-6038| |753 |Customer#000000753|17 |27-817-126-3646| |754 |Customer#000000754|0 |10-646-595-5871| |755 |Customer#000000755|16 |26-395-247-2207| |
Congrats! You just ran your first query on Trino. Did you feel the rush!? Okay well technically we just copied data from a data generation connector and moved it into a MySQL database and queried that back out. It’s fine if this simple exercise didn’t send goosebumps flying down your spine but hopefully you can extrapolate the possibilities when connecting to other datasets.
A good initial exercise to study the compose file and directories before jumping into the Trino installation documentation. Let’s see how this was possible by breaking down the docker-compose file that you just ran.
| version: ‘3.7’ services: trino-coordinator: image: ‘trinodb/trino:latest’ hostname: trino-coordinator ports: – ‘8080:8080’ volumes: – ./etc:/etc/trino networks: – trino-network mysql: image: mysql:latest hostname: mysql environment: MYSQL_ROOT_PASSWORD: admin MYSQL_USER: admin MYSQL_PASSWORD: admin MYSQL_DATABASE: tiny ports: – ‘3306:3306’ networks: – trino-network networks: trino-network: driver: bridge |
Notice that the hostname of mysql matches the instance name, and the mysql instance is on the trino-network that the trino-coordinator instance will also join. Also notice that the mysql image exposes port 3306 on the network. Last configuration to point out is that mysql will point to a relative directory on the local filesystem to store data. This can be cleared out when completed.
Finally, we will use the trinodb/trino image for the trino-coordinator instance, and use the volumes option to map our local custom configurations for Trino to the /etc/trino directory we discussed before in this post. Trino should also be added to the trino-network and expose ports 8080 which is how external clients can access Trino. Below is an example of the docker-compose.yml file. The full configurations can be found in this getting started with Trino repository.
These instructions are a basic overview of the more complete installation instructions if you’re really going for it! If you’re not that interested in the installation, feel free to skip ahead to the Deploying Trino at Scale with Kubernetes section. If you’d rather not deal with kubernetes I offer you another pass to the easy button section of this blog.
Trino requirements
The first requirement is that Trino must be run on a linux machine. There are some folks in the community that have gotten Trino to run on Windows for testing using runtime environments like cygwin but this is not supported officially. However, in our world of containerization, this is less of an issue and you will be able to at least test this on Docker no matter which operating system you use.
Trino is written in Java and so it requires the Java Runtime Environment (JRE). Trino requires a 64-bit version of Java 11, with a minimum required version of 11.0.7. Newer patch versions such as 11.0.8 or 11.0.9 are recommended. The launch scripts for Trino bin/launcher, also require python version 2.6.x, 2.7.x, or 3.x.
Trino Configuration
To configure Trino, you need to first know the Trino configuration directory. If you were installing Trino by hand, the default would be in a etc/ directory relative to the installation directory. For our example, I’m going to use the default installation directory of the Trino Docker image, which is set in the run-trino script as /etc/trino. We need to create four files underneath this base directory. I will describe what these files do and you can see an example in the docker image I have created below.
- config.properties – This is the primary configuration for each node in the trino cluster. There are plenty of options that can be set here, but you’ll typically want to use the default settings when testing. The required configurations include indicating if the node is the coordinator, setting the http port that Trino communicates on, and the discovery node url so that Trino servers can find each other.
- jvm.config – This configuration contains the command line arguments you will pass down to the java process that runs Trino.
- log.properties – This configuration is helpful to indicate the log levels of various java classes in Trino. It can be left empty to use the default log level for all classes.
- node.properties – This configuration is used to uniquely identify nodes in the cluster and specify locations of directories in the node.
The next directory you need to know about is the catalog/ directory, located in the root configuration directory. In the docker container, it will be in /etc/trino/catalog. This is the directory that will contain the catalog configurations that Trino will use to connect to the different data sources. For our example, we’ll configure two catalogs, the mysql catalog, and the tpch catalog. The tpch catalog is a simple data generation catalog that simply needs the conector.name property to be configured and is located in /etc/trino/catalog/tpch.properties.
tpch.properties
| connector.name=tpch |
The mysql catalog just needs the connector.name to specify which connector plugin to use, the connection-url property to point to the mysql instance, and the connection-user and connection-password properties for the mysql user.
mysql.properties
| connector.name=mysql
connection-url=jdbc:mysql://mysql:3306 connection-user=root connection-password=admin |
Note: the name of the configuration file becomes the name of the catalog in Trino. If you are familiar with MySQL, you are likely to know that MySQL supports a two-tiered containment hierarchy, though you may have never known it was called that. This containment hierarchy refers to databases and tables. The first tier of the hierarchy are the tables, while the second tier consists of databases. A database contains multiple tables and therefore two tables can have the same name provided they live under a different database.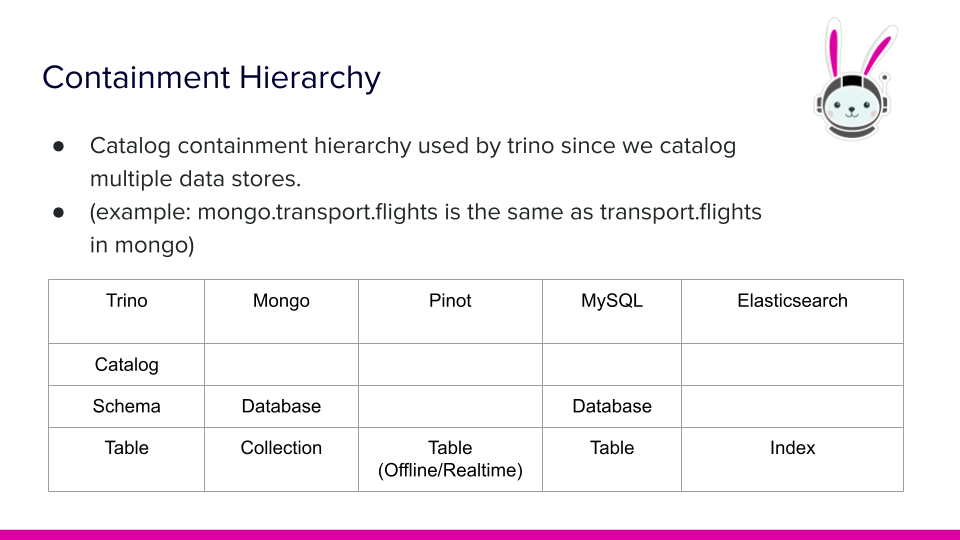
Since Trino has to connect to multiple databases, it supports a three-tiered containment hierarchy. Rather than call the second tier as databases, Trino refers to this tier as schemas. So a database in MySQL is equivalent to a schema in Trino. The third tier that allows Trino to distinguish between multiple underlying data sources are made of catalogs. Since the file provided to Trino is called mysql.properties it automatically names the catalog mysql without the .properties file type. To query the customer table in MySQL under the tiny you specify the following table name mysql.tiny.customer.
If you’ve reached this far, congratulations, you now know how to set up catalogs and query them through Trino! The benefits at this point should be clear, and making a proof of concept is easy to do this way. It’s time to put together that proof-of-concept for your team and your boss! What next though? How do you actually get this deployed in a reproducible and scalable manner? The next section covers a brief overview of faster ways to get Trino deployed at scale.
Deploying Trino at Scale with Kubernetes
Up to this point, this post only describes the deployment process. What about after that once you’ve deployed Trino to production and you slowly onboard engineering, BI/Analytics, and your data science teams. As many Trino users have experienced, the demand on your Trino cluster grows quickly as it becomes the single point of access to all of your data. This is where these small proof-of-concept size installations start to fall apart and you will need something more pliable to scale as your system starts to take on heavier workloads.
You will need to monitor your cluster and will likely need to stand up other services that run these monitoring tasks. This also applies to running other systems for security and authentication management. This list of complexity grows as you consider all of these systems need to scale and adapt around the growing Trino clusters. You may, for instance, consider deploying multiple clusters to handle different workloads, or possibly running tens or hundreds of Trino clusters to provide a self-service platform to provide isolated tenancy in your platform.
The solution to express all of these complex scenarios as configuration is already solved by using an orchestration platform like Kubernetes, and its package manager project, Helm. Kubernetes offers a powerful way to express all the complex adaptable infrastructures based on your use cases.
In the interest of brevity, I will not include the full set of instructions on how to run a helm chart or cover the basics of running Trino on Kubernetes. Rather, I will reference you to an episode of Trino Community Broadcast that discusses Kubernetes, the community helm chart, and the basics of running Trino on Kubernetes. In interest of transparency, the official Trino helm charts are still in an early phase of devel




