
This is Part 2 of a 2-part blog about how Trino can support both interactive and batch use cases. In Part 1, we explored the case for why an organization needs both interactive and batch capabilities and why Starburst is the simplest way to run both using the same platform. In Part 2, we will go through a detailed tutorial of how to set up a batch job using Trino and Starburst Galaxy.
I deeply despise surprises. Not the “I got you a puppy!” surprises but the “wait, that wasn’t supposed to fail” surprises that elicit a special combination of confusion and heartbreak. I hate the way my body reacts, the increase in heart rate, the hand sweating, and the stress knot in my stomach that miraculously appears around the same time my brain starts shuffling through expletives. Some developers LIVE for the rush of adrenaline, but not me. I like my data pipelines like I like my toast: plain and bug-free.
Alas, a world without failures is not one that data engineers live in. Things happen, sometimes jobs fail, and there is absolutely no postmortem reason discovered as to why the job worked on one run but didn’t work on the next. Sometimes we are unluckier than others, and the job that fails could be supporting an executive-level fraud trend dashboard that gets scrutinized every morning. This failure is painful. Don’t ask me how I know that.
Trino is my favorite interactive query engine because of its speed, cost-based optimizations, and ANSI SQL support. However, there was historically no query failure recovery so if that executive-level dashboard on fraud trends had a task fail, there would be empty dashboards the next morning. While failures were statistically unlikely with a proper Trino setup, the historic absence of fault tolerance at both the query and task level made the stakes a little more like playing with fire.
Good news! Due to the recent implementation of a new fault-tolerant execution architecture and granular task retries, specifically for the ETL/ELT workloads, guardrails have been added so that you can easily utilize Trino for your long-running or batch queries. If you want to learn more about the Trino implementations, I highly encourage you to check out this trino-tastic blog. The authors dive into some tested findings of Trino with both fault-tolerance enabled and disabled, and the results are astounding.
I know we are all wondering, did Starburst Galaxy also get some features around ETL/ETL workloads to make our lives easier? Spoiler alert: Yes it did, and it’s awesome. In this blog, I want to demonstrate the revolutionary new additions around enabling batch clustering in Starburst’s fully managed cloud offering.
Starburst Galaxy
Acting as the curious individual that I am and building on the information I read about in the Trino blog, I conducted an experiment using the TCP-H dataset, specifically the SF300 schema, that is preloaded into Starburst Galaxy. I tapped into my 7th-grade science fair knowledge (and Google) to make sure I am representing the Scientific Method accurately, and have thus come up with the following problem statement.
Problem Statement: How do TPC-H queries on an interactive cluster perform against running the same queries on a batch cluster when there are constrained resources (an X-Small cluster)? In essence, what is the benefit of running in batch mode?
I guess the correct “term” is Problem Statement(s), but you know, semantics. To analyze our final results, we will create two clusters in Starburst Galaxy, and run some queries in the environment. If you would like to follow along with me, the only pre-experiment setup required is to create a Starburst Galaxy account.
Creating Clusters in Starburst Galaxy
To complete our experiment, we will start by creating both an interactive cluster and a batch cluster in Starburst Galaxy. Both clusters will use the TPC-H Catalog (which is pre-defined for us) and will be defined to the US East (Ohio) AWS region. I will walk you through the steps for cluster creation below, and I also demonstrate my own cluster creation in video format.
How to Create an Interactive Cluster
First, log in. If this is your first time, Woohoo! Congrats, and I am happy to be a part of this journey with you. Upon login, you should see the Query Editor. To create a cluster, go to the Cluster pane on the left-hand panel. This should take you to a page that has a Create Cluster button at the top. This is where, you guessed it, we will create our clusters.
Our first cluster should be named something identifiable for interactive queries, I named mine interactive. While we will be using X-Small clusters, fear not as they are only 2 credits/hour and Starburst Galaxy trial comes with $500 dollars worth of credits so there will be plenty left over for more exploration. The other configurations are below.
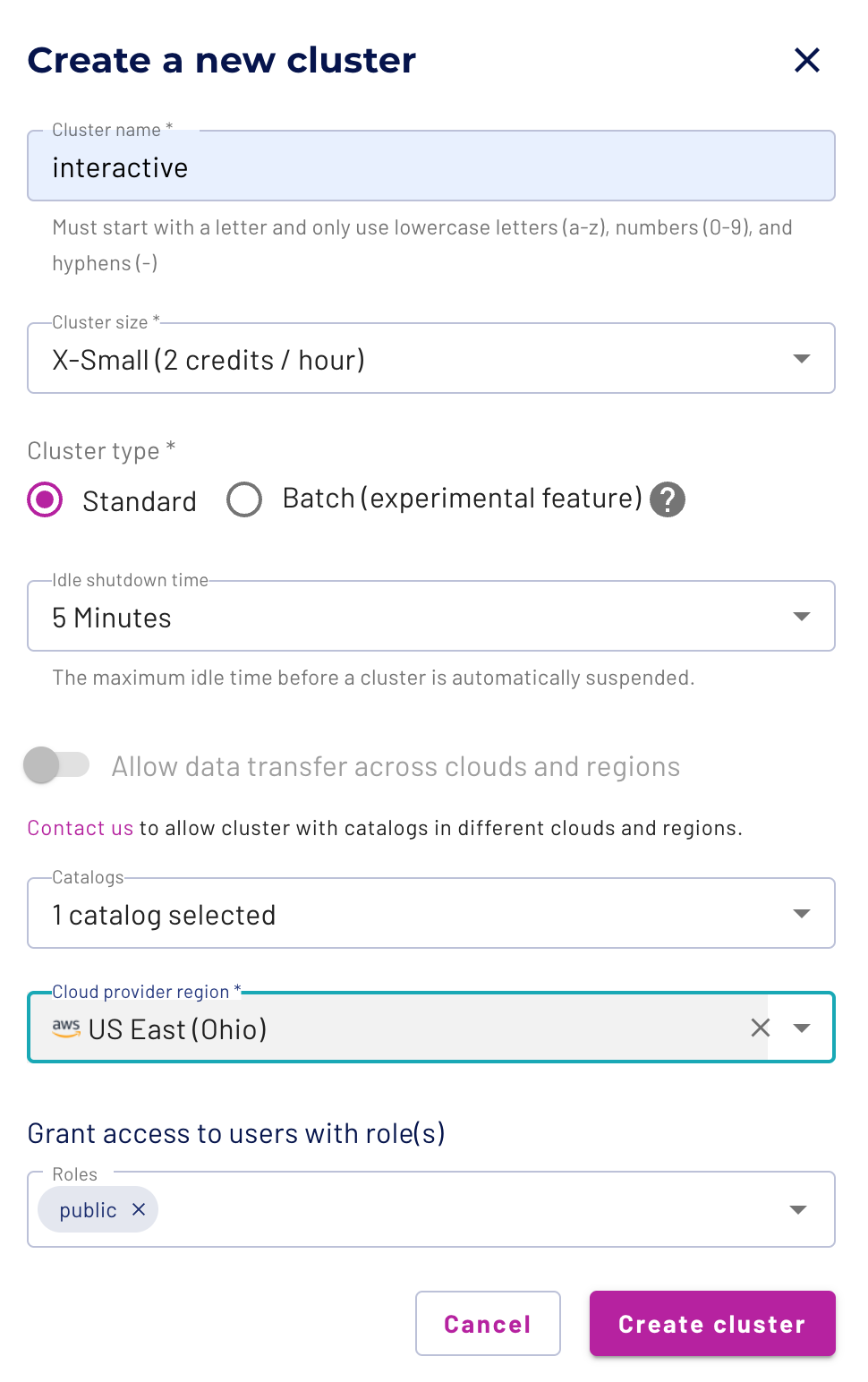
Cluster Size:X-Small (2 credits / hour)
Cluster Type: Standard
Idle Shutdown Time: 5 Minutes
Catalog: tpch
Cloud Provider Region:US East (Ohio)
Click the create cluster button, and Voila! First one created. You will also see the cluster starting up to be able to be queried.
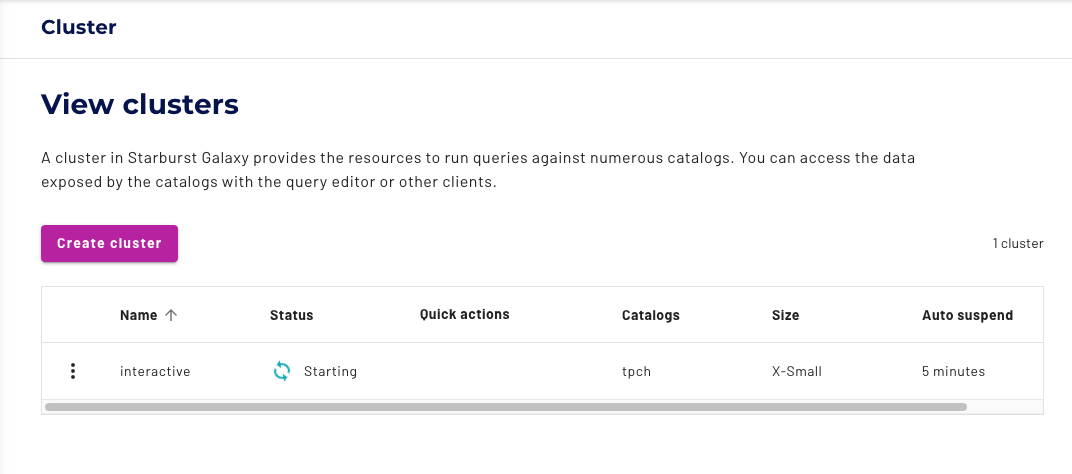
How to Create a Batch Cluster
Creating the batch cluster is very similar to creating the interactive cluster. We will start by clicking the create cluster button again in the upper left corner. Name this cluster with some sort of identifier for batch processing, I named mine batch. We want the cluster configurations to be identical to the interactive cluster except for the Cluster Type, which will be batch.

Cluster Size:X-Small (2 credits / hour)
Cluster Type: Batch
Idle Shutdown Time: 5 Minutes
Catalog: tpch
Cloud Provider Region:US East (Ohio)
Double Voila! We now have created both of our clusters and can proceed forward.
Query Creation
I now want to use these X-Small clusters to run a standard query and see the outcome. I created this query very interactively, as I got to play around with the data already available in Starburst Galaxy and develop a use case for my hypothetical scenario. Again for standardization, I am running the same query, with the same catalog, on two different clusters. The only difference between the clusters is the cluster type, with the interactive cluster being a standard cluster and the batch cluster being a batch cluster.
I have created a video demonstrating my experiment execution if you prefer to follow along (and be thoroughly amazed) visually.
Interactive Cluster Results
I’m going to first run this query on the interactive cluster and view the results. I do this by navigating to the query editor and selecting the following dropdowns in the top right corner.
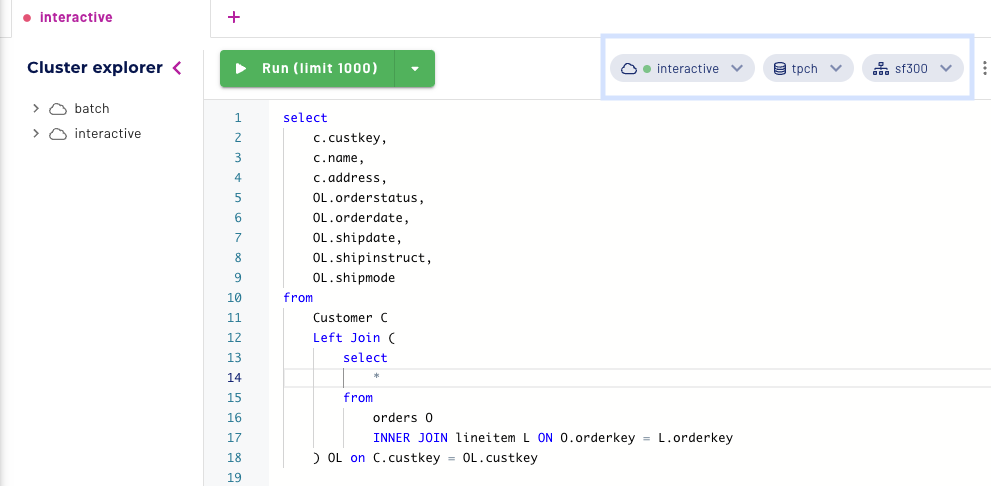
Cluster:interactive
Catalog: tpch
Schema:sf300
Next, hit Run.

Failure! Oof. We hit a task-level failure that ended up failing our query. Check out the Trino UI link, which shows which stage the query failed on, the stack trace error message, and each task. I really enjoy the Trino UI, and I highly recommend exploring all the beneficial information it has to offer.
The Error Information should not surprise us, as it matches what we alluded to in the Galaxy Query Editor.
|
Error Type |
INSUFFICIENT_RESOURCES |
|
Error Code |
EXCEEDED_LOCAL_MEMORY_LIMIT (131079) |
Scrolling down to the bottom of the overview and finding the task-specific information, here is what I see.
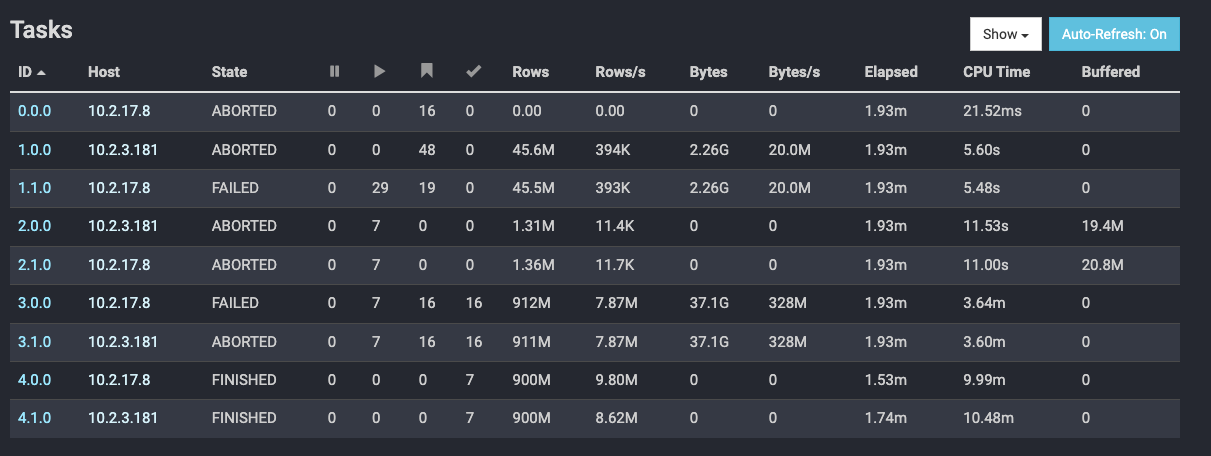
Notice all the Task IDs have an X.X.0 configuration. The task identifier is in the format: stage-id.task-id.retry-id. Since the retry-id’s are all 0, no retries occurred on a FAILED task state, which aborted the entire query.
Batch Cluster Results
Switching clusters from Interactive to Batch from the query editor using the cluster selection in the top right, I am now going to run the same query and see what results we get.
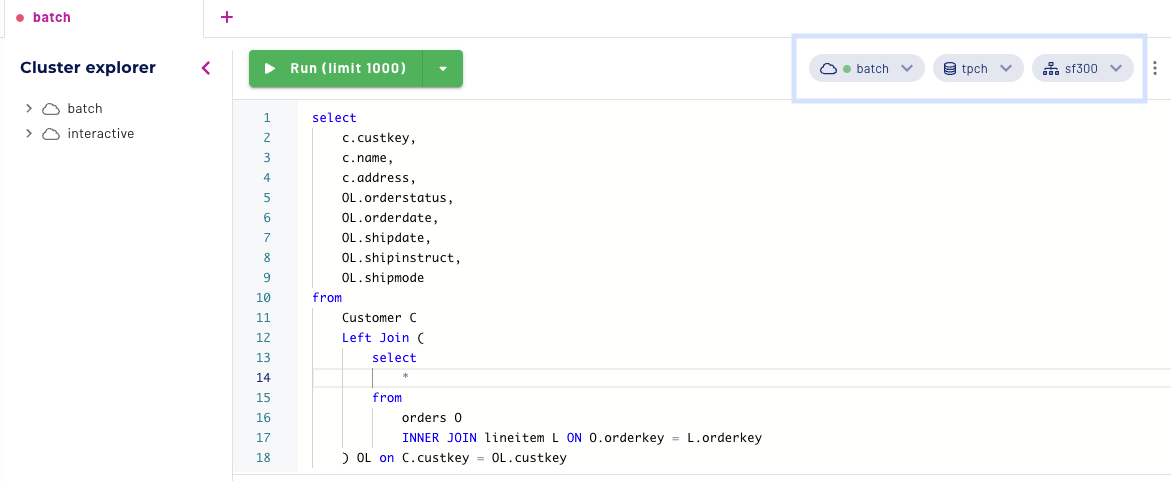
Cluster: batch
Catalog: tpch
Schema:sf300
Drumroll, please…..
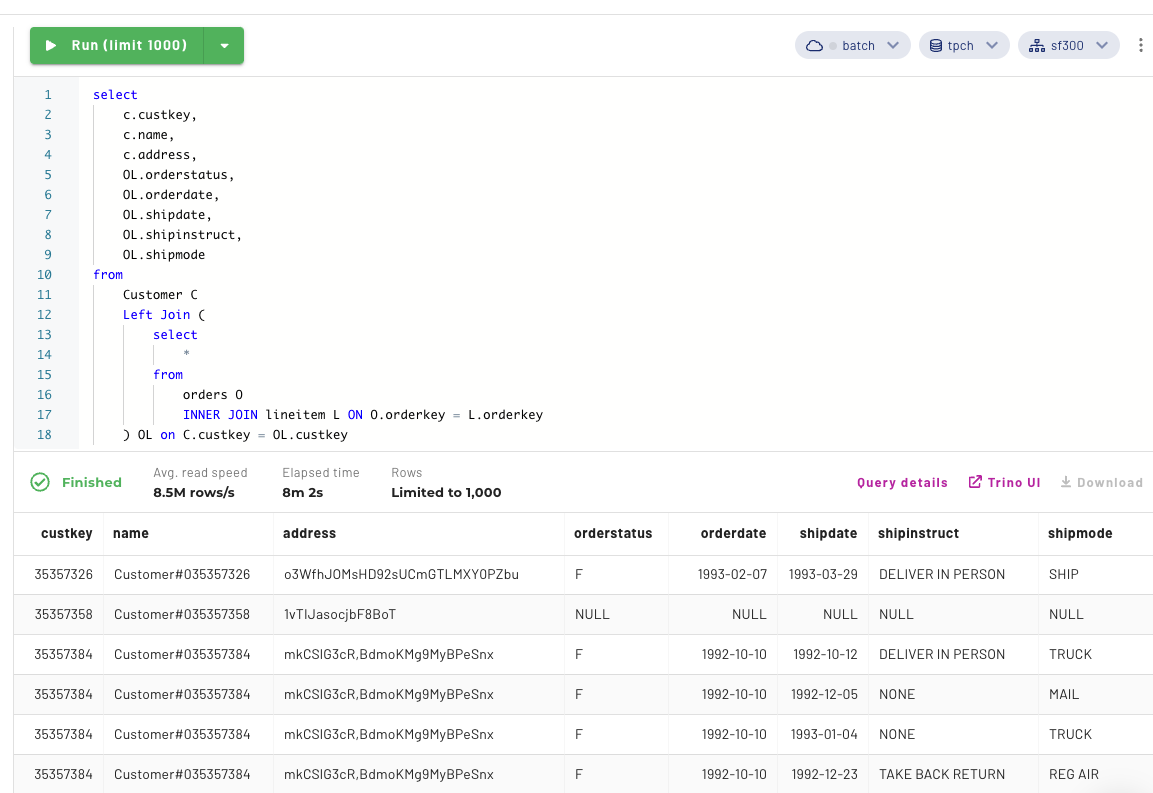
Well, Well, Well… look at that beautiful query information. While it took quite a bit of time, we can see the query successfully answered our question. So, what’s the deal? Let’s look into our Trino UI again and compare the results from our failed query to now.

After opening the Trino UI and scrolling down to the tasks, there are some obvious tasks that failed, but because of the task retry implementation the query could continue. Below is a subsection of some of the tasks that were executed to get the query to finish. If we look at 1.0.0, it is shown that the original attempt failed. Then, 1.0.1, the task retry which picked up after the 1.0.0 failed, completed. This is again all thanks to the wonderful capabilities that have been implemented specifically to make the enablement of batch clusters easier.
How do you pick a Batch vs Interactive cluster?
Hopefully, after walking through this experiment with me, we have established that this new functionality is awesome and can open up new possibilities when it comes to executing ETL/ELT workloads. But how do you know what the limit is, or when to pick the right type of cluster? The secret is all about knowing your data and understanding the tradeoffs. It comes down to four main factors that must be considered when deciding which is right for you: Speed, Automation, Cost, and Trustworthiness. If you want to read more about these factors, I invite you to visit my article weighing the pros and cons of each point.
Here’s the secret! If you accidentally pick the wrong option, the cluster can easily be updated, which reinforces the importance of optionality and the benefit of having a technology that can easily interchange between interactive and batch querying.
Starburst Galaxy:
There are many other features that reinforce Starburst Galaxy’s capabilities as life-changing when it comes to data management. Some of my favorites include:
- Increased Developer Efficiency
- Expert Support and Domain Expertise
- Query History / Logging Capabilities
- Cost Control via idle shutdown features
If you would like to share your experience with Starburst Galaxy, or the results of your own experimentation, engage with us on Trino Forum. We would love to hear your feedback. You can try Galaxy for free with up to $500 in free credits.




