

Data Mesh is based on four central concepts, the third of which is self-service data infrastructure. In this blog, we’ll explore what that means and delve into the details of what makes this a fundamental shift supporting a decentralized data ecosystem.
What is self-service data infrastructure?
The idea behind a self-service data infrastructure is that a business is made up of logically autonomous domains; each domain not only supports a business function, product, or process, but also produces data products and therefore requires a data infrastructure to do that. The domain should not be tasked with managing that underlying data infrastructure themselves, but rather should be enabled by a central IT organization to use a provided self-service data platform. This platform allows the domains to focus on building high-quality data products that ultimately garner business value in the form of data analytics.
The platform itself is built and maintained by the central IT organization, and is domain agnostic. This allows for customization and extensibility as needed by each domain, but further prevents the domain from going down a “shadow IT” infrastructure development rabbit hole. Moreover, this gives the domain’s engineers the freedom to mature and design end-to-end solutions that they build and maintain without succumbing to enforcement of design or vendor constraints by an overarching central IT authority. Ultimately this enables creation of efficient design, and generally coherent data products.
The challenges with centralized infrastructure
Many existing platforms and technologies are built with an assumption of a centralized data team, capturing and sharing data for all domains. This was largely necessary with legacy infrastructure and the limitations of older technologies, but these limitations are no longer present thanks to the onset of cloud computing and easily scaled hardware and applications. Assumptions around centralized control of applications and infrastructure have deep technical consequences such as how computation and storage are allocated, how organizations are structured, how data is made available for business purposes, and more. These assumptions ultimately serve to block domain teams acting autonomously.
In a centralized infrastructure model, the biggest challenge is that domains who develop data products are forced to work with the provided software – which may or may not be suited to the work the domain engineers are doing. For example, if storage and compute resources are handled exclusively by central IT, the domain will need to either work around the parameters set by IT, or work with IT to make domain-specific changes. In that case, the “loudest” domain may dominate the infrastructure in a way that doesn’t work for other domains. On the other hand, when a central data architecture design is forced onto a domain without considering the domain’s specific goals and data, some domains will end up with inefficiencies and frustrations due to tooling and infrastructure optimized for other domains.
A related risk with purely centralized infrastructure is the rise of “shadow IT” organizations, as mentioned above. When domains build out their own infrastructure to suit their specific needs in a fully decentralized model, this is not only a governance risk, but it misses out on the economies of scale benefit that a centralized organization could create.
Self-service infrastructure in the Data Mesh
In a Data Mesh, the self-service platform will provide functionality across the mesh, from the storage and compute capabilities up through consumption. The central IT organization supplies a development platform that allows domain engineers to focus on domain-specific development; the central IT organization would also be responsible for tuning the infrastructure in a way that makes sense for the domain.
It’s important to note that virtualization of data, rather than centralization, is an important construct in Data Mesh. Rather than physically moving data to a central store and requiring complex coordination between pipelines and disparate technologies, Data Mesh encourages data producers to use a federated platform with a common language, such as SQL, to provide a virtualized layer for “publishing” data products. Virtualization allows domains to be somewhat “airgapped” from the technology underneath, focusing entirely on business value rather than infrastructure. Of course, the data infrastructure platform will evolve as domain requirements for data evolve, but the infrastructure will remain the purview of the central IT organization. This has the benefit of vastly improving time-to-value for data, greatly reducing complexity and sensitivity to changes, and increasing flexibility both for the data producers and consumers.
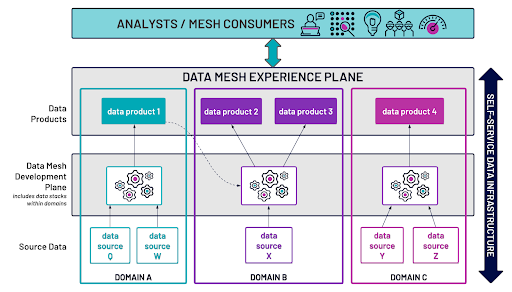
The goal of Data Mesh is to provide a blend of centralized infrastructure enabling domains to do what is best for their business needs. This means that the platform should have a low barrier for adoption, and provide ease of interoperability with other common tools that are used by data engineers and data consumers alike. The infrastructure should allow the domain to own the code, data, and policy that makes up a data product and focus on creating business value from data, rather than getting bogged down in maintenance of tooling or infrastructure.
The set of resources and tools which makes up the self-service data infrastructure platform must provide functionality including (but not limited to) the following:
This approach has the benefit of avoiding duplicated efforts across domains with infrastructure development, while also avoiding domain-specific infrastructure efforts where possible. Further, for purposefully federated efforts such as governance, the shared infrastructure across domains allows for ease of administration as well as economies of scale in resource cost management.
What does this look like in practice?
From a practical perspective, the self-service data infrastructure platform is absolutely necessary simply so the data product developers are not overloaded by the additional demands of building a data infrastructure. Data engineers, analytics engineers, and infrastructure engineers are three particularly overloaded professions – each group is expected to demonstrate cross-domain and cross-functional expertise at an unprecedented scale. To avoid overloading any of these roles, a clear delineation of duties and responsibilities is paramount.
One way to do this is to break up the data infrastructure into two entities: the data and the infrastructure.
- The data refers to the data model, the schema, transformation rules, ETL/ELT pipelines, metadata, and any related applications of domain-specific knowledge. This is the responsibility of the domain.
- The infrastructure refers to the resources which enable any domain to create and maintain data products. This includes installation, maintenance, upgrading, scaling of the tools and resources used to the domain-specific data product creation. This is the responsibility of the central IT organization.
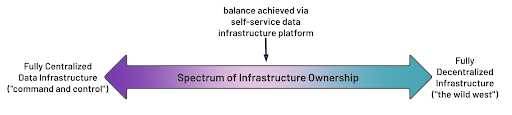
As shown above there is a spectrum of responsibility for the self-service data infrastructure platform – where an organization falls on that spectrum should be clearly defined and agreed upon by the domains and central IT organization together. Furthermore, costs and any chargeback models should be contracted between the domains and central IT so there is no confusion of responsibilities. These models can be applied to a small number of domains or data products to start, and then iterated upon as more domains are onboarded into the Data mesh.
In practice, an example of a component or service of the self-service infrastructure could be a data catalog tool. The vendor agreement, installation, maintenance, upgrades, and user authentication would be handled by the central IT organization. However, the actual use of the tool to define the catalog entry for a specific data product, and ensuring its correctness, reliability, and adherence to any domain-specific or organization-wide standards would be the responsibility of the individual domains.
How does this enable Data Mesh?
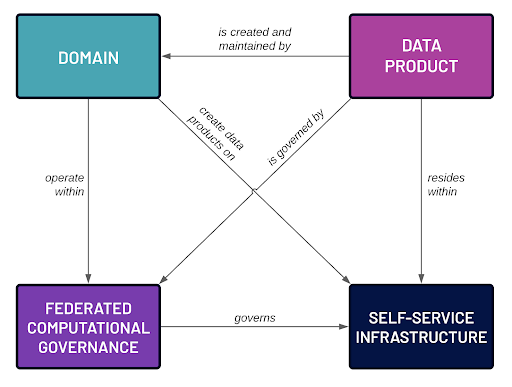
Quite simply, the self-service data infrastructure is the physical backbone of the Data Mesh:
- Central IT chooses vendors and tools based on the needs of domains, and evolves the infrastructure along with the domains’ needs over time.
- Domains use the provided data platform to create and maintain data products in the way that is most efficient and sensible for their specific domain requirements.
- The centralized portion of the federated computational governance (that is, any global governance concerns that are defined at the corporate level) is enforced at the infrastructure platform level
- The decentralized portion of the federated computation governance (that is, any domain-specific governance concerns) is enforced by the domain using the self-service infrastructure platform.
- Data products are published to consumers and are used within infrastructure and tools provided and maintained by the central IT organization
How Starburst supports self-service data infrastructure
Legacy data platforms and technologies are largely built with the underlying assumption that the data platform is controlled and maintained by a central organization, but also that any data produced or consumed must use the same infrastructure. Curation of data products must happen within that centralized infrastructure and there are both organizational and technical consequences for this paradigm, as discussed at length in recent times.
One key tenet for a forward-thinking data infrastructure is that it be built for a generalist audience. Functionally, this means:
- The majority of users should be comfortable with the technology
- The platform should scale appropriately
- There must be a low barrier to entry and adoption
- New tools and technologies must be easily onboarded as advances are made in the market
Starburst, of course, handles all of these requirements with ease, and can function as both the data product creation and consumption layer for a Data Mesh. On the creation side, Starburst can act as the core of the self-service data infrastructure platform. The central IT organization installs and maintains Starburst for use by the domains, allowing data engineers to use SQL to create data products efficiently and simply by connecting various data sources and curating data into downstream datasets fit for consumption by analysts.
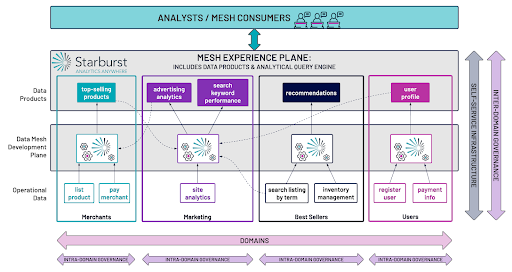
When working with Starburst, users are able to access their data with SQL – this means data engineers and analysts benefit from ease of use in a simple language they already know, which in turn results in increased adoption for the data platform both with and across domains. This is incredibly important – Starburst provides a single endpoint to all of the data technologies for the domain data product developers as well as the consumers, which promotes simplicity and focus on the core business value, rather than learning new languages or technologies.
Starburst integrates seamlessly with other vendors in the DataOps, cataloging, governance, visualization, and machine learning spaces, ultimately providing a solid foundation for the self-service data infrastructure platform that is simple and scalable, with lightning-fast performance. By serving as both the self-service data infrastructure platform used by the domains and the query engine behind the Data Mesh experience plane, Starburst lowers the barrier to entry and refocuses the problem space around the business logic rather than building complex pipelines.
Interested in learning more about how Starburst can get you up and running with a self-service data platform? Contact us to discuss!




