

Data Mesh is based on four central concepts, the fourth of which is federated computational governance. In this blog, we’ll explore what that means and delve into the details of what makes this a fundamental shift supporting a decentralized data ecosystem.
What is federated computational governance?
As we know from our previous discussions of domain-oriented ownership, data as a product, and self-service data infrastructure, Data Mesh is all about the shift from centralized data teams and architectures to a decentralized model. This gets particularly interesting when thinking about what governance functionality remains under the purview of the central IT organization, and what is now the responsibility of the domain. While the overall shift in Data Mesh is from a one-size-doesn’t-fit-all centralized architecture to a choose-your-own-adventure decentralized architecture that is optimized for the domain, there are aspects of data governance that will necessarily need to remain with a central group in order to strike a balance and ensure all aspects of governance are adequately provided for.
Defining governance
Governance can encompass a great many things, but for our purposes we will focus our discussion of governance on getting the right data to the right people at the right time. This means considering the following in terms of data governance:
- Security: are the right people authenticated and authorized to use the data?
- Compliance: does the data follow any and all required policies, e.g. GDPR, RTBF, etc.?
- Availability: is the data accessible by authorized users?
- Quality: is the data quality in some way quantified and communicated to users?
- Entity Standardization: is there agreement on terminology across domains?
- Provenance: is it clear who is responsible for the data and where it came from?
It’s clear that some of these aspects of governance will be set at the mesh level, whereas some are at the discretion of the domain. Data Mesh allows for this shared responsibility with a federated governance model, allowing for global standards and policies that are applied across domains, while allowing domains to have a large degree of autonomy for how those standards and policies are implemented within the domain.
Computational governance
With governance in Data Mesh focused on a balance between interoperability and global standards, the question arises of how to enforce that governance – this is where the “computational” part comes into play. This is a challenging body of work, and to automate that enforcement of compliance is key. Via automation of conformity to regulations and standards, domains should be following standard devops and infrastructure-as-code practices to apply governance – hence computational governance.
The challenge with centralized governance
In a fully centralized, non-federated governance model, the above initiatives are fully prescribed by a central IT organization, which presents challenges. For example, data quality is something that a central IT organization will not be able to speak to – each domain must define the quality standards and measurements that apply to its own data products. Data provenance will be specific to the domain, as well; though the self-service infrastructure may be what is used to express that provenance through cross-domain lineage and catalog capabilities, the business knowledge inherent in data transformations affecting lineage belongs to the domains. While risk and compliance initiatives and requirements are defined at the corporate level, it’s typically the domains which implement the compliance activities (e.g., flagging or masking PII).
The common theme here is that while some governance activities and standards must be defined and enforced at the mesh level, the lack of specific business knowledge at the mesh level presents an implementation challenge. Moreover, while setting cross-domain standards can allow for commonalities among domains, they can also impede delivery velocity within a domain if the governance requirements are not built with the domain in mind.
Federated Computational Governance in the Data Mesh
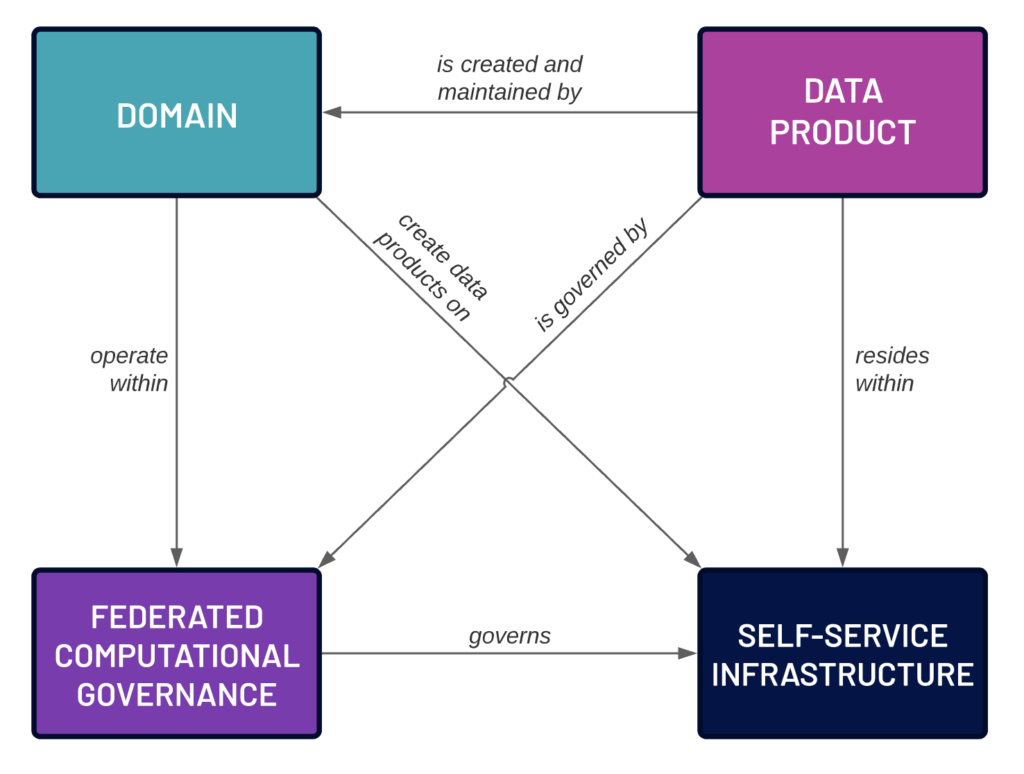
Data Mesh proposes a shared responsibility between the domains and the central IT organization in order to adhere to governance while allowing adequate autonomy for the domains. It’s important to note that this is a federated model, meaning that there is a cross-domain agreement as to which aspects of governance are handled at the mesh level, and which are handled by the domains.
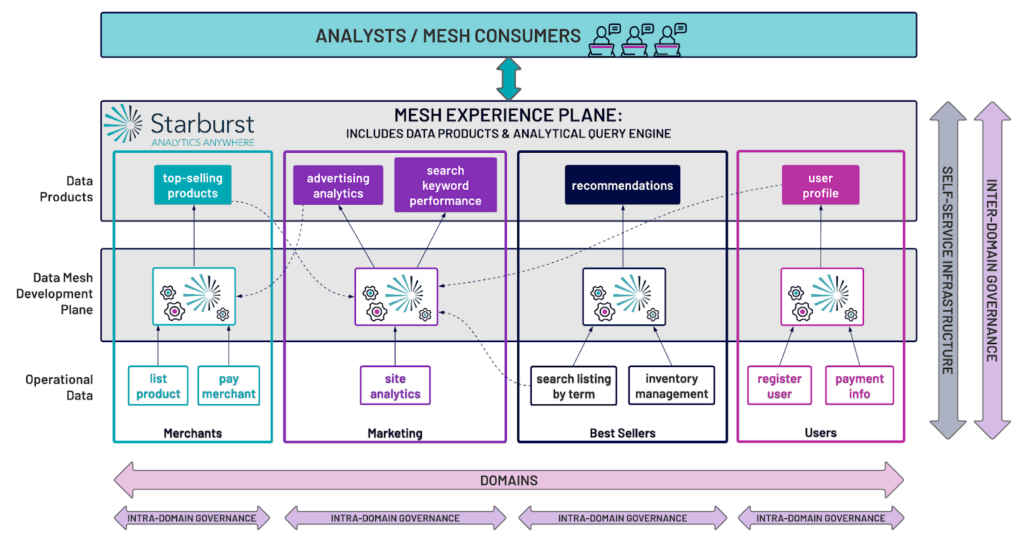
Intra-domain governance
The domains typically will take responsibility for quite a few facets of governance that in a fully centralized model would have been left to the central IT team. We sometimes call this “intra-domain governance.” For example, data quality for a data product is now the responsibility of the domain. Functionally this means that when creating a data product, the domain team must define quality standards for that product and then measure those standards on a defined cadence, publishing the quality information alongside the data product. The provenance of the data product must also be identified and available from the domain. In the case where a Domain A ingests data products from another Domain B, Domain B is responsible for the provenance and quality of the data product that it produces and is consumed by Domain A. Further, Domain A is also responsible for notifying Domain B of any data product changes in order to ensure clarity and consistency of quality across data products. Consistency of data entity terminology within the domain (intra-domain entity standardization), likely in the form of a data dictionary or communicated to a cross-domain data catalog, is also the responsibility of the domain – this is all defining metadata that is arguably part of the data product, and is under the purview of the domain. Authorization entitlements are nearly always defined and managed at the domain level, as the data product developers are the subject matter experts on the data in the data products
Inter-domain governance
On the other hand, there are aspects of governance that must be defined external to the domains, at the mesh level. We sometimes call this “inter-domain governance.” Using the data quality example from above, we could require that when a data product is published to the mesh it must report its data quality, note this is not defining the specific data quality aspects such as thresholds, but simply that data quality must be quantified and reported. Another example is compliance to regulatory policies (e.g., GDPR, CCPA/CPRA, etc.) that may be controlled/implemented by the domain and reported at the mesh level. Global entitlement reviews can track entitlements across and into domains, ensuring compliance and data security. There is also standardization of terminology across domains (inter-domain data entity standardization) which is used to ensure that for broadly applied terminology, domains agree and adhere to the agreed upon definition. After all, the domains must have the same definition of “customer” and “sale” for mesh users to be able to join together data products and thereby create new business value. By contrast to authorization, authentication is nearly always defined at the mesh level within a company, and then applied using policy objects such as groups and roles.
A shared model
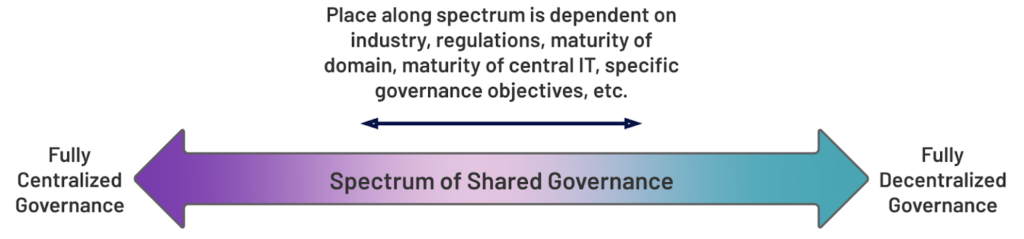
The bottom line is that rather than dictating a command-and-control centralized governance function without consideration for the nuances of each domain, the Data Mesh paradigm espouses a federated governance model. This means balancing the needs and specific knowledge of the domain with the overarching requirements of the business to produce a division of responsibility that is clearly articulated and agreed upon. The image below depicts a “spectrum of shared governance” – where a company lands on that spectrum between the centralized and decentralized governance models will depend on the maturity of the central IT and domain organizations, governance objectives and requirements, industry, and regulatory environment, among other things.
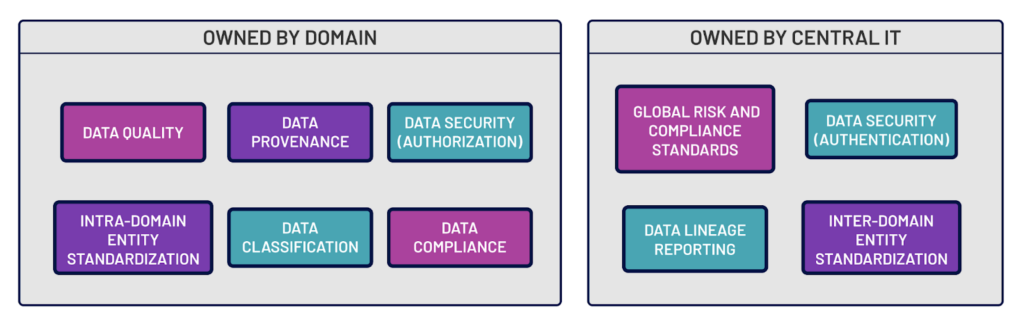
What does this look like in practice?
In practice there are particular characteristics of what governance will look like in any given organization that may differ from others. Typically, however, central IT will own data lineage reporting, inter-domain standards, authentication, and articulation of the global risk and compliance standards and policies. The domains therefore would own data quality (both definition and measurement), data provenance, authorization, data classification, adherence to compliance and terminology standards, and definition of inter-domain data entity standardization.
There are, of course, cases where many of these may be something that circumstances dictate should be controlled at the alternative level, but again this should be clearly articulated and agreed upon by the domains and the central IT and governance organizations. An effective way of handling this is to have a representative from each domain who is a member of a cross-domain governance council, which works with the central IT and governance organizations to define and agree upon ownership. In a parallel to typical Agile development, this agreement (or “contract”) should be articulated initially as early data products come online, and then iterated upon as the mesh becomes more mature. Also note that compliance and standards change periodically and require audits, therefore having an appointed person (data product owner) from each domain will help with ownership of the responsibilities for those audits – typically a challenge in any organization.
Center of Excellence for Data Governance
Imagine a group of domain owners working with the central IT organization, designing overarching governance rules which will apply to the domains, and then agreeing on what governance work will be the responsibility of the domains themselves. This group would be a center of excellence for data governance, with an overall group leader managing the governance roadmap for shared data governance aspects such as cross-domain entity standardization and compliance standards. The CoE leader serves as a liaison with the owners of the respective domains, and focuses on details of the governance partnership with each domain team. This well-defined relationship articulating responsibility of the domains and central IT clarifies ownership and details of the shared governance model, fostering reuse where possible and encouraging cooperation between domains.
How does this enable Data Mesh?
A federated computational governance model is key to enabling and driving the other three principles governing Data Mesh:
- Domains have a well-defined framework and set of responsibilities to operate within
- Data products are governed by and will adhere to clear standards, increasing confidence of both users and regulators
- The shared governance model gives a clear set of requirements to the central IT organization, defining what is required for the self-service data infrastructure both in terms of toolsets and compliance.
How Starburst supports federated computational governance
At its core, Starburst shortens the path between the data and the business value derived from the data. What this means in the context of a federated computational governance model is that a domain can rely on Starburst to support the shared responsibilities of the domain and the central IT team in the quest for well-governed data. Our software allows for the application of data security to be defined and automated by the domain using a built-in delegated authorization system.
Moreover, Starburst supports open standards to enable seamless integration with governance tools such as data catalogs and lineage products and data security platforms. There is also a significantly reduced need to copy datasets or data products as Starburst’s query engine can read across data sources and can replace or reduce a traditional ETL/ELT pipeline. Copying datasets also requires copying or reapplying entitlements, which can result in potential opportunities for data breach or exposure – with Starburst that risk is minimized simply because fewer copies of the data will exist. This also speaks to data minimization – with data sprawl across organizations, data discovery and data security are exponentially more challenging. By minimizing data sprawl (via minimizing data replication), data privacy, security, and governance are more achievable goals.
Starburst provides connectors and access to open APIs and catalogs such as Collibra, Alation, Amundsen, Marquez, and DataHub, which expose much of the metadata required to discover, understand, and evaluate the trustworthiness of data.
Want to learn more about how Starburst can help you build a Data Mesh? Contact us to discuss!




