
Despite the investments and effort poured into next-generation data storage systems, data warehouses and data lakes have failed to provide data engineers, data analysts, and data leaders trustworthy and agile business insights to make intelligent business decisions. The answer is Data Mesh – a decentralized, distributed approach to enterprise data management.
Founder of Data Mesh Zhamak Dehghani defines Data Mesh as “a sociotechnical approach to share, access, and manage analytical data in complex and large-scale environments – within or across organizations.” She’s authoring an O’Reilly book, Data Mesh: Delivering Data-Driven Value at Scale and Starburst, the ‘Analytics Engine for Data Mesh,’ happens to be the sole sponsor. In addition to providing a complimentary copy of the book, we’re also sharing chapter summaries so we can read along and educate our readers about this (r)evolutionary paradigm. Enjoy Chapter Six: Principle of Self-Service Data Platform!
So far, Zhamak has challenged current data architectures and suggested a brand new paradigm towards Data Mesh: a distributed data architecture with ownership based on business domains, and proposed a new architectural unit, data as a product.
However, these two principles on its own, raise a few concerns:
- Duplication of efforts in each domain
- Increased cost of operation, and
- Most importantly, large scale inconsistencies and incompatibilities across domains.
Zhamak acknowledges that “expecting domain engineering teams to own and share analytical data as a product, in addition to building and managing applications and products, raises legitimate concerns for both the practitioners and their leaders.”
These concerns gave way to Data Mesh’s third principle: self-serve data infrastructure as a platform. One key differentiation of data platforms that will enable a Data Mesh implementation: the ability to scale out sharing, accessing and using analytical data, in a decentralized manner.
First, let’s understand how Data Mesh’s technical platform is different from many existing solutions we have today.
Data Mesh Platform’s Differentiating Characteristics
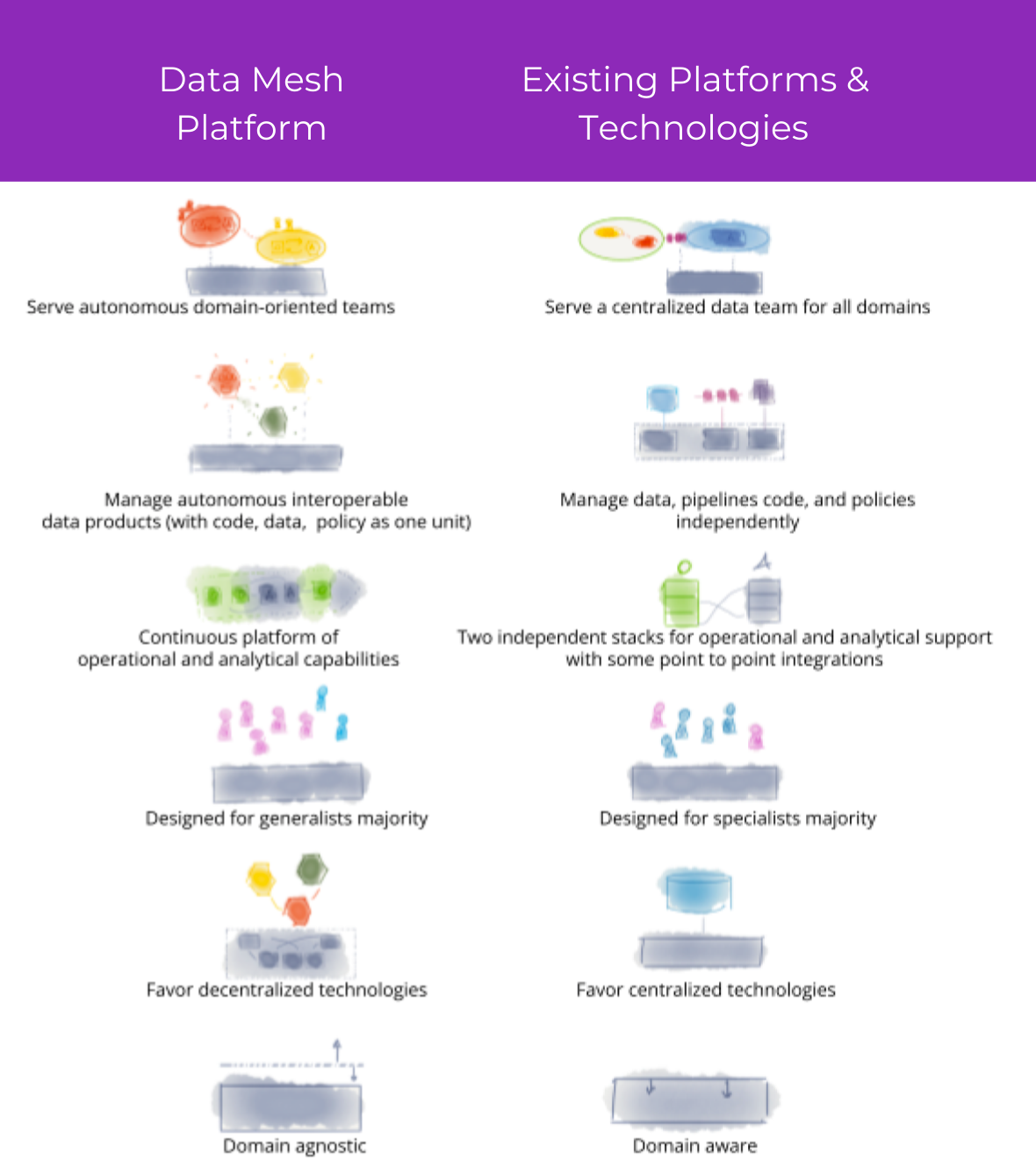
To elaborate on the needs of a Data Mesh self-serve platform and to differentiate it from today’s available existing platforms, technologies and approaches, the table below highlights the key differences:
Data Mesh Platform |
Existing Platforms & Technologies |
| Serves autonomous domain-oriented teams
A Data Mesh platform must enable domain teams to operate autonomously, without dependencies on centralized or intermediary data teams. This approach helps teams with new and embedded responsibilities of creating, sharing, and using data products throughout their lifecycle. |
Serves a centralized data team for all domains
Centralized control results in deep technical consequences for how compute and storage are allocated, how resources are structured, and limits the autonomy of a team. |
| Manages autonomous and interoperable data products
Data Mesh centers on domain-oriented data products, which autonomously and inherently deliver value. Embedded within data products are: discoverability, usability, trustworthiness and secure data to its end data consumers. As such, Data Mesh platforms must support managing its autonomous lifecycle and all its interconnected components. |
Manages data, pipelines code, and policies independently
Today’s existing technologies do not encourage interdependence, but embrace independent functionality. For instance: data processing pipelines, data and its metadata, and data governance policy all exist independently. |
| Continuous platform of operational and analytical capabilities
Whether the team is creating, sharing or using data products, an ideal Data Mesh platform would provide a more connected, cross-functional domain-oriented experience. This experience would in essence, close the gap between analytical and operational planes. |
Two independent stacks for operational and analytical support with some point to point integrations
With a centralized infrastructure, operational and analytical data are presented as separate stacks and a fragmented landscape of platforms. That can make the data landscape challenging to navigate, and it makes it harder to produce trustworthy insights. |
|
Designed for generalists A Data Mesh platform must incentivize and enable generalist developers with experiences, languages and APIs that are easy to learn, and can be used independent of the underlying vendor. This would be a wonderful start to reduce the cognitive load for generalist developers. |
Designed for specialists
The result of mammoth monolithic data platforms and the proprietary knowledge that each technology vendor requires have led to the creation of very scarce (and therefore expensive) specialized roles such as data engineers. |
| Favoring decentralized technologies
Data Mesh’s singular focus on decentralization through domain ownership organizational bottlenecks that ultimately impede agility and change. At first glance, it may appear to be solely an organizational concern, however, the technology foundation of an organization directly influences how it communicates and collaborates. |
Favoring centralized technologies
A monolithic or centralized technology approach leads to centralized points of control and teams. Examples include centralized versions of all of these:
|
| Domain agnostic
The select Data Mesh platform requires a thorough understanding of the data developers and consumers and the application of product thinking. Why? The responsibilities are reflected in the Data Mesh platform capabilities. For instance, “the platform must strike a balance between providing domain-agnostic capabilities, while enabling domain-specific data modeling, processing and sharing across the organization.” A carefully chosen Data mesh platform will enable two very clear responsibilities:
|
Domain aware
Currently, most data teams are responsible for both domain-specific data for analytical usage, as well as the underlying technology infrastructure. |
In summary, below are a set of characteristics of a Data Mesh platform(left), in contrast to existing platforms and technologies(right).
Key Objectives of Data Mesh Platform Thinking
Now that we’ve outlined some of Data Mesh’s self-serve platform needs, let’s take a closer look at top-level objectives of Data Mesh adopting the concept of platform thinking.
Enable Autonomous Teams to Get Value from Data
Ideally, when a Data Mesh platform functions smoothly, it enables domain teams to independently get their work done and accomplish business goals with a sense of autonomy and without having to rely on another team. When designing domain teams, it is helpful to consider the roles within each team, and their data journey in sharing and consuming data products to ultimately create business value. There are many other roles (i.e. data product owner) we can consider and plan for when creating a frictionless experience, however, for now, let’s focus on the two main roles of Data Mesh: data product developers and data product consumers.
Enable Data Product Developers, Autonomously
A data product developer is responsible for managing the entire lifecycle of a data product: creating it, building it, testing it, deploying, monitoring, updating, and maintaining its integrity and security. This is all in concert with code, data and policy.
Accordingly, a successful Data Mesh platform will have versatile, domain-agnostic, and cross-functional capabilities that will enable a data product developer to build, test, deploy, secure and maintain a data product.
Enable Data Product Consumers, Autonomously
A frictionless and fully functioning Data Mesh platform facilitates a seamless data product journey and provides the capabilities needed for data product consumers to get their job done without a bottleneck or minimal manual intervention.
A data product consumer’s journey always starts with discovering the data. Once discovered, the consumer will need access to the data, so she can understand it and take a closer look. Upon inspection, if the data proves itself to be useful, it will remain in circulation. Using data isn’t a “once-and-done” process. Consumers should continuously receive and process novel data to produce up-to-date insights and/or maintain machine learning models.
Exchange Value with Autonomous and Interoperable Data Products
As a catalyst for organizational and cultural shifts, the Data Mesh platform promotes sharing and consuming autonomous data products between two or more groups, for instance: data product developers, data product owners and data product consumers. The key performance indicator of a Data Mesh platform is measured by a frictionless exchange of value of data products between data consumers and data providers.
Zhamak guides us, “The value can be exchanged on the mesh, between data products, or at the edge of the mesh, between the end products such as an ML model, a report or a dashboard, and the data products. The mesh essentially becomes the organizational data marketplace.”
Accelerate Exchange of Value by Lowering the Cognitive Load
To simplify and accelerate the productivity of domain teams in delivering value, we need to hide technical and foundational Data Mesh platform complexity from domain teams. This reduces the team’s cognitive load and redirects their focus on what matters to the business: creating and sharing data products.
Platforms are increasingly popular as a way to reduce the cognitive load of developers to accelerate their tasks and reduce time-to-insight. This is done by hiding complex detail and information presented to the developer, also known as abstracting complexity.
How Data Mesh Scales Data Sharing
Data Mesh essentially solves the problem of organizational scale in getting value from their data. That’s why the platform must operationally scale and enable data sharing across domains within an organization, as well as outside the organization. We also know that data has limited value if it’s not shared, therefore a Data Mesh platform must design for secure interoperability across multiple platforms to share data products. Without a standard, we fall back to a single monolithic solution that limits the scale of our operation.
Zhamak uses observability as an example of a capability that a Data Mesh platform should offer: “the ability to monitor the behavior of all data products on the mesh and detect any disruptions, errors, and undesirable access; and notify the relevant teams to recover operation. Even for a simple capability such as observibility, there are multiple platform services that need to cooperate:
- the data products emitting and logging information about their operation
- the service that captures the emitted logs and metrics and provides a holistic mesh view
- the services that search, analyze, and detect anomalies and errors within those logs
- the services that notify the developers when things go wrong
The key to integration of these services is interoperability, a common language and APIs by which the logs and metrics are expressed and shared.”
How Data Mesh Creates a Culture of Innovation
As of late, continuous innovation must be a core competency of any business. A Data Mesh platform removes unnecessary manual labor, hides complexity, streamlines data workflows, and frees data product developers and consumers to perform data-driven experiments and innovate.
According to Zhamak, “To assess the efficacy of a Data Mesh platform: measure how long it takes for a domain team to ideate a data-driven experiment, get to use the data to run the experiment. The shorter the time, the more mature the Data Mesh platform has become.”

The image above depicts an overall Data Mesh platform objective applied to domain teams: sharing and using data products.
6 Ways to Get Started: Self-Serve Data Mesh Platform
If you’ve bought into the Data Mesh paradigm, here are a few steps you can take to build your Data Mesh platform today.
#1 First Design the APIs and Protocols
Whether you are buying and/or building a Data Mesh Platform, start with selecting, and designing the interfaces that platform exposes to its users. The interfaces might be programmatic APIs, shared as libraries, command line or graphic interfaces. Regardless, first decide on interfaces and then implementation.
#2 Prepare for Generalists’ Adoption
A Data Mesh platform must be designed for the generalist. Select platform technologies that are in line with a natural style of programming known to many developers. This approach will build resilient and maintainable data products.
#3 Create APIs to Manage Data Products
While many services from cloud data platforms include lower level utility APIs, a Data Mesh platform often introduces a new set of higher level APIs to manage data products as a way of abstraction.
#4 Converge Data and Operational Platforms, Where Possible
As data products integrate with the operational world, there is a real need to integrate their platforms. That’s why a Data Mesh platform is a catalyst in simplifying a technology environment and creates a collaborative effort between operational and analytical platforms.
#5 Build Experiences, Not Mechanisms
Platforms should enable experiences, not mechanisms. Your Data Mesh platform can start with a single experience of ‘discovering data products’. Then, build or buy the simplest tools, mechanisms, that enable this experience. Then iterate and recalibrate for the next experience.
#6 Start Building a Data Mesh Strategy Today
Zhamak has one simple piece of advice to get started, “Begin adopting a Data Mesh strategy today, even if you don’t have a Data Mesh platform.”
Your framework is most likely composed of the big data technologies that you’ve already adopted. As the number of your data products grow and the standards evolve, you’ll continue to iterate the platform by auditing and sharing common capabilities across data products and domain teams.
Read along with us!
Get your complimentary access to pre-release chapters from the O’Reilly book, Data Mesh: Delivering Data–Driven Value at Scale, authored by Zhamak Dehghani now.




