

Data Mesh is based on four central concepts, the second of which is data as a product. In this blog, we’ll explore what that means and delve into the details of what makes this a fundamental shift supporting a decentralized data ecosystem.
What is a data product?
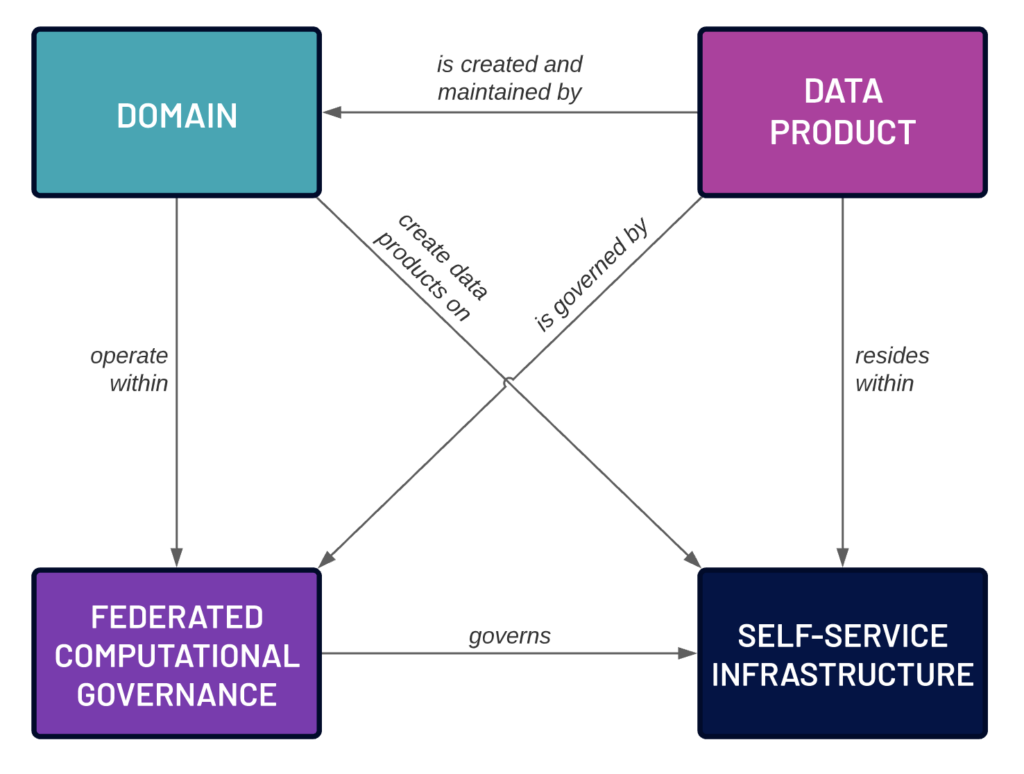
A data product is data that is served by a domain and consumed by downstream users to produce business value. The data product is the heart of the Data Mesh — it is created and analyzed and combined with business knowledge to allow businesses to use data to answer questions — without the data product, a business cannot reach the goal of being data-driven.
In its simplest form, a data product is simply data — a location of a table perhaps. However, as with most things in the data world, the real answer is a bit more complex:
- The first piece of a data product is, of course, the data: files, tables, views, streams, etc.
- In order for that data to be useful to an end user (say, an analyst), they need to understand the data, which means they need its metadata: columns, definitions, number of rows, refresh patterns, etc.
- Access patterns are a specific type of metadata useful in instructing end users how to query the data and what engine to use
- The code used to create the data product is actually a meta-part of the data product
- The infrastructure used to create the data product is another meta-part of the data product
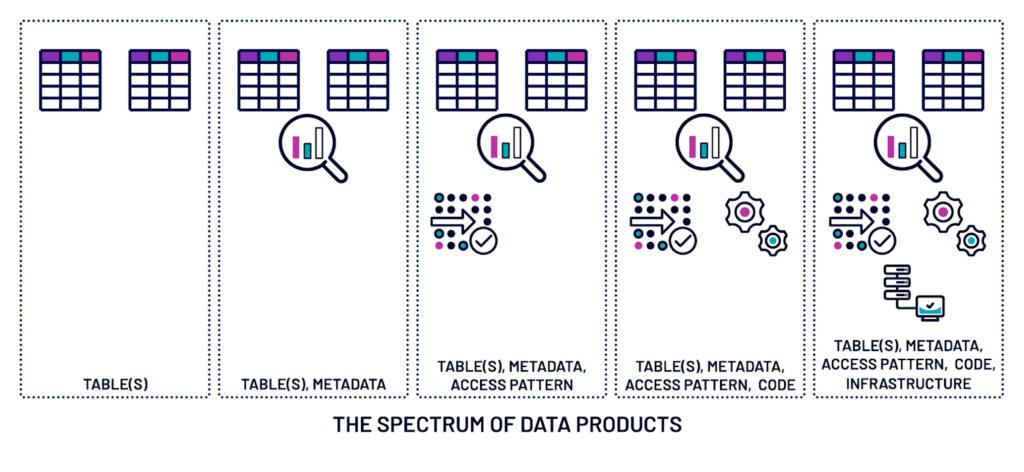
It’s the combination of all of these — data, metadata, code, and infrastructure — that make up the data product. Note that each data product produced by a domain is valuable in its own right, even if it’s a simple aggregate being used in a single report, e.g. monthly sales by region. In fact, a data product can range from a simple, cleansed list of transactions to a highly curated and complex group of datasets.
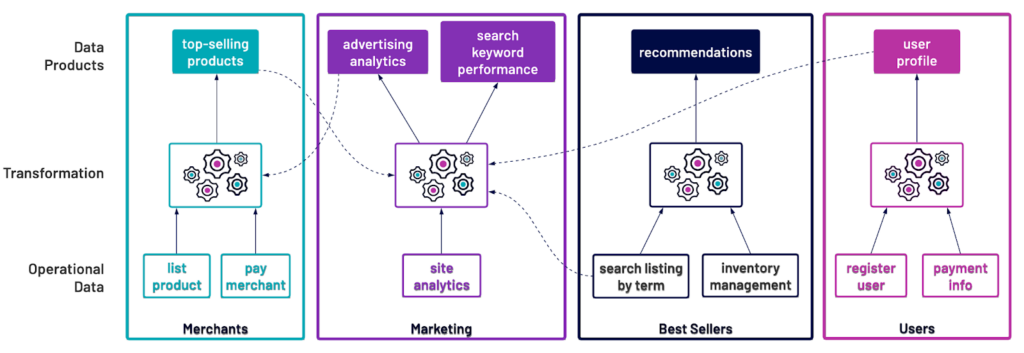
In practice, data products are frequently far more complex, and can even be used to produce other data products within the same or different domains. For example, user profile information can be combined with top-selling product information to drive marketing efforts, which are in turn used to create advertising analytics data products.
The challenges with centralized data ownership
Aren’t all companies these days aiming to be “data-driven” and use data in strategic business decisions? Doesn’t everyone know data is the new oil and growing exponentially and the world’s most valuable asset?
This may be old news to most people, but reports show that real challenges arise when companies try to compete with analytics and data. When it comes time to invest in data and insights from that data, companies will often create a data and analytics infrastructure and team to centralize data knowledge cross-functionally. Perhaps this works when a company is small and nimble, but as businesses grow and mature so, too, must their data and analytics strategy.
A breakdown of epic proportions
Take, for example, a customer service team at an ecommerce company. Their main focus is providing excellent service to their customers, answering questions and fulfilling orders to drive business. The team also creates data — data about incoming requests, call sentiment analysis, resolution timelines, etc. This data is never analyzed by this team — instead it’s pushed over the fence into a central data warehouse where data engineers and analysts are expected to clean, aggregate, transform, and analyze the data — all of which requires deep expertise around the specifics of the customer service organization. Data engineers and analysts must therefore become experts in all subject areas and their underlying technologies across the company, a Herculean if not impossible task. Furthermore, the variety of disparate data sources being pushed or pulled into the central data infrastructure means those same data engineers need to be cross-functional data pipeline experts, as well.
This fragile centralized data ecosystem is destined to fail as the company grows and becomes more complex. We’ve seen these problems repeatedly with the data warehouse and data lake paradigms. With a lack of clear ownership and clarity around who owns each piece of the data product, the value potential of data is destined to get lost in the chaos.
Data Products in the Data Mesh
Data Mesh aims to clarify and prescribe that the ownership and architecture of data products belongs to the domain, but further that data is treated as a first-class product across the organization. This is a drastic mental shift, wherein data is no longer treated as a by-product of activities that the business engages in, but as a business product in its own right. It’s been shown time and again that there is inherent product-level and game changing value in data; data is a key value-driver that should aggressively direct business decisions. Businesses should therefore invest in creating and managing that data with the same care and forethought that they do other products and services.
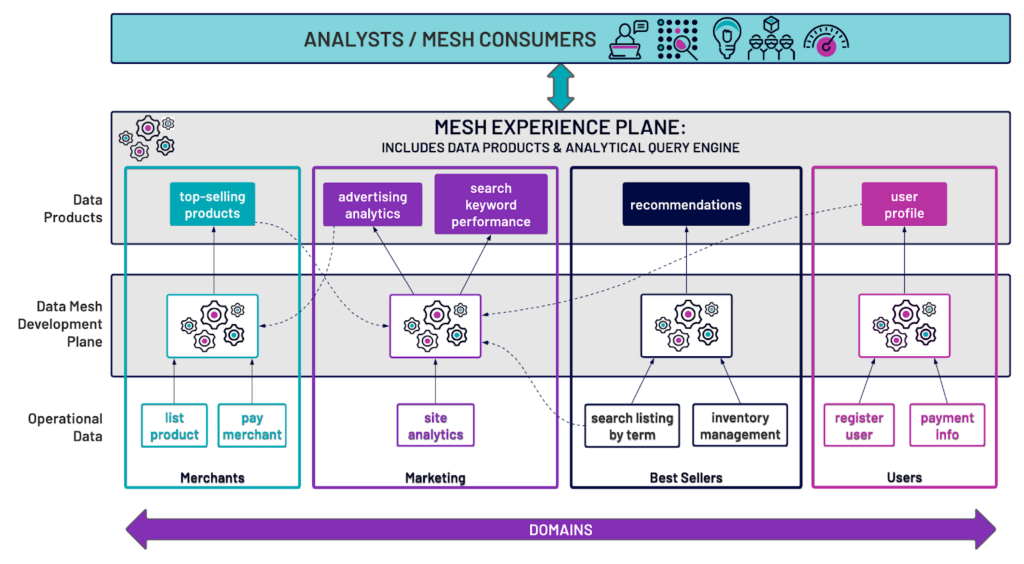
By incorporating a unified understanding of and agreement upon what constitutes a data product cross-functionally, businesses can then adopt a framework that enables domains to produce data within that structure. That treatment of data as a top-line product of business domains provides a cultural and functional standard across the company which informs all data producers and consumers that data is a precious commodity. Moreover, by moving responsibility and ownership of the data products back into the domains (and away from a centralized team), the development of the data product sits with the subject matter experts who understand the data best. This means that the end data product will ultimately be more valuable, more trustworthy, and more clearly defined.
What’s this DATSIS?
Data Mesh’s goal is to allow end users easier access to data so that they can derive business value faster and more reliably. Moreover, Data Mesh clarifies the roles that the domain and the central IT team play, which helps avoid any “shadow IT” either in the domains or among the analytics folks. To that end, the ideal data product has several qualities that drive this goal as well as overall data governance. The goal is to make data:

The handy acronym DATSIS allows us to remember the key elements of a data product, and the domains producing these data products should design their products to conform to these standards.
What does this look like in practice?
Going back to our example above of the ecommerce customer service group. Imagine a dedicated data engineer now sits within the group developing the functionality driving the customer support activities. That data engineer is now an expert in that data, and understands the nuances of creating it, cleaning it, defining metadata and a catalog, and ultimately serving it to the rest of the company. Further, the data engineer can facilitate the collaboration of the operational system owner and the business analyst, which is often a lost cause in a centralized architecture.
From a downstream perspective, an analyst looking into the trends of support call timing as a function of marketing activity in a certain metro region can be confident that the data product is clean and that they understand it well. Another user creating golden customer records can use this product to create the column “average number of monthly support requests” for each customer in the aggregated data product.
Versioning data products in a maturing Data Mesh environment
One thing to note is that with the decentralization of data products, versioning (that is, the changing definition of a data product over time) becomes a simpler proposition. As a traditional large data pipeline is broken into smaller, modular, and more manageable data products, the changes within those data products must be considered. If a data product changes, any downstream users of that data product must have visibility into those changes and a method of handling them. Via standard processes, data consumers can be informed about both breaking and non-breaking changes in a data product, as well as retirement of data products. The centralized analytical plane for use of data products can provide telemetry and usage information on data products, to allow domains (data product owners) to understand and work with consumers on how data products should evolve and better serve their end users.
How does this enable Data Mesh?
Treating data as a product is key to enabling and driving the other three principles governing Data Mesh:
- Data as a product enforces the value of data by an organization, and ensures that data is understood to be a worthy investment across the company
- Domain-driven ownership and architecture of data products means the people with the most subject matter expertise (the domain) will be the driving contributor to the data product, and will be responsible for its quality, metadata, performance, etc.
- Data products reside within the self-service infrastructure provided and maintained by the central IT organization
- Inter-domain security, compliance, and regulation for data products are defined and enforced by the central IT organization
- Intra-domain governance including authorization is applied to each data product by the domain
How Starburst supports a data products architecture
At its core, Starburst shortens the path between the data and the business value derived from the data. What this means in the context of producing data products is that a domain can rely on Starburst to allow data engineers to focus less on building infrastructure and pipelines to support data engineering efforts. Data engineers can instead focus more on using simple tools they already know, such as SQL to prepare high-quality, low-latency data products for end users. There is also a significantly reduced need to copy datasets or data products as Starburst’s query engine can read across data sources and can replace or reduce a traditional ETL/ELT pipeline.
Starburst is also used at the cross-domain analytical layer as the query engine which streamlines and simplifies data product access by analysts and data scientists. This emphasis on empathy for the end user is inherent in Starburst’s design, along with the ease of use for data engineers, is incredibly important and powerful.
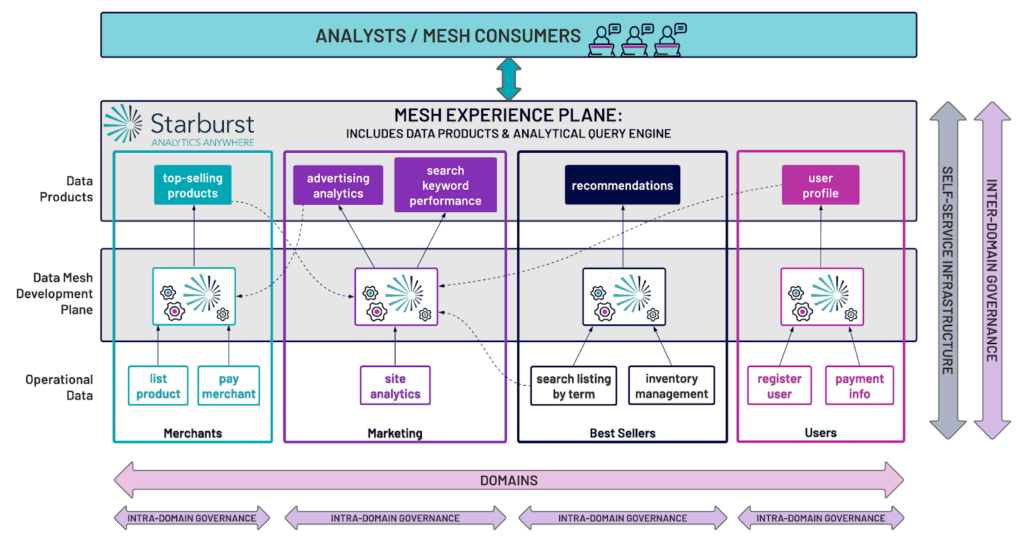
Starburst also provides connectors and access to open APIs and catalogs such as Amundsen, Marquez, and DataHub, which expose much of the metadata required to discover, understand, and evaluate the trustworthiness of data. Starburst also provides telemetry around data product usage which helps with prioritization and consumption pattern recognition of data products by consumers. Our solution further allows for data security to be built-in via delegated authorization inherited from the governance system.
Want to learn more about how Starburst can help you build data products? Contact us to chat!




