

In our last post, we covered how to determine whether Data Mesh is right for your organization. It was a post that we extended from the most recent Datanova: The Data Mesh Summit into this two-part series. You can decidedly bring back the learnings to both your analytics and business teams.
When organizations are ready to implement Data Mesh, they require another level of strategy and approach. So, once you’ve determined your level of commitment, the next step is to take a look at the Data Mesh execution model, which centers on transformation as the key pillar, which drives execution through business initiatives and delivers value, end to end.
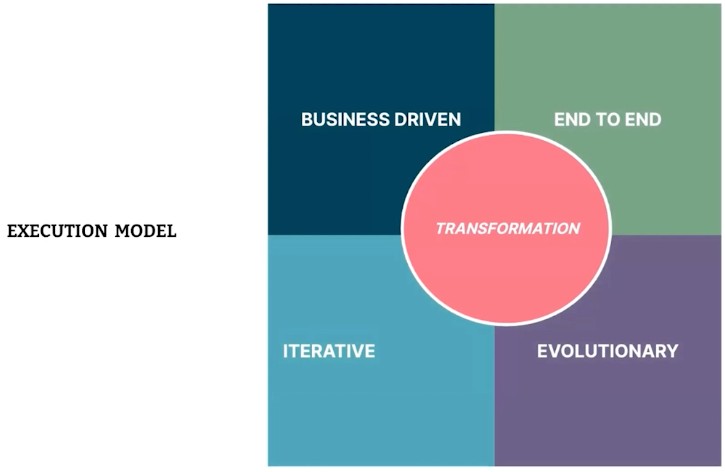
#1 Delivering value, end to end
One challenge organizations must confront when they’re executing big transformational programs is that they prove value, every step of the way which requires foundational capabilities. For instance, creating a data platform requires an enormous upfront investment as well as a time commitment to build the platform. Keep in mind that if the program doesn’t demonstrate value along the way, it can potentially compromise the trust of the organization in terms of investing in the platform.
#2 Iterative approach
An evolutionary and iterative approach to getting to the target state is imperative. If we were to build point solutions only to satisfy the business initiatives, we wouldn’t build the foundation for reuse and scale. Therefore, we need to strike a balance between having an iterative approach and a business-driven approach.
#3 Business-driven approach
A business-driven approach is multi-pronged, but it most often starts with the business use cases. The next step involves identifying the personas of the data users you have in your organization — data scientist, data analyst, etc. Don’t forget to identify key personas so that the platform satisfies the native tools with the data users.
By the way, there’s an art to identifying complementary use cases: balancing point solutions and the YAGNI (You Aren’t Gonna Need It) principle, which edits excess and inefficiency in development to facilitate the desired outcome. An example that considers complementary use cases is to select data analysts and data scientists with reporting as a use case. When you’re building the platform, it’s not hyper-specialized to one persona and not the other. In essence, they complement each other really well.
Keep in mind that you might not have to build all of the platform capabilities upfront. Start with simpler use cases and have simpler dependencies assigned to new features of the platform. Over time, you’ll end up with a brand new platform.
#4 Multi-phase evolutionary adoption model
When considering an evolutionary execution, we don’t need to start with the target state of scale. Yes, we want to have an impact, but the implementation and what we’re going to execute to unlock the business capabilities will look very different when we’re bootstrapping. Consider the main pillar around which you will be evolving both your operating model and your technology. The business impact of your Data Mesh implementation at the beginning of the bootstrapping phase is very different from the final business impact.
Bootstrapping to scale with Data Mesh

As you’re starting, select a few high-value, but low complexity use cases, so that you can continue to invest while getting initial value. The reality is that you won’t reach exploitation — a return on investment — until you get to the scale phase.
As far as the number of domains go, you’ll have less number of domains. In terms of self-serve infrastructure, satisfy a smaller set of common patterns of building data products.
Once you achieve scale, you become more diverse in terms of how you support your teams. However, when you’re first getting started, in terms of team structure, start a project with one use case, a couple of domains, a handful of data products, and you can even begin a centralized team. But as you scale, you can start decentralizing those teams.
S-Curve of diffusion for Data Mesh
For another vantage point, a tool you can use to design this evolutionary model for Data Mesh is Roger Everett’s Diffusion of Innovation, the S-Curve of diffusion of innovation. Why? In essence, you’re diffusing a new approach to your data within your organization.

On the X-axis, there are various adopters of this new approach to data within your organization. You start with your early adopters, early majority, then you go to late majority and laggards.
And as you go through the S-curve, you accelerate the number of adopters and you somewhat stabilize. And this S-curve doesn’t happen once. In fact, this S-curve happens repeatedly, many times, every time after a big shift happens within your organization.
How? If you’re an adopter now, you can potentially take this approach to a new business unit, or maybe you even change your technology partner to a new technology. So there are various reasons and events that would cause this S-curve to repeat itself many times.
The bottom line is that this model will give you a few different phases to optimize your execution for each of these adoption phases. So if you’re bootstrapping, you’re optimizing for exploration. If you’re scaling, you’re optimizing for expanding adoption to many teams. And if you’re in the exploit phase, you’re optimizing for consistency and getting value without disruption.
Empowering Early Data Mesh Adopters
In this two-part series, the primary focus has been for early adopters to see what a possible journey might be like once the organization commits to investing in Data Mesh. They’re paving the path and establishing the kind of practices that often become the sensible defaults for organizations. When you, as an early adopter, move to the sustain or the exploit phase, you are now optimizing for the laggard, not those that pave the path, but the organizations that are following the path. Best wishes in your Data Mesh journey – from all of us at Starburst!




